Glǽmscribe – Der Transkriptor für Tolkiens Sprachen
Glǽmscribe (oder Glaemscribe) ist eine von Benjamin Talagan Babut geschriebene Open Source Engine und Bibliothek zur Umschrift von J. R. R. Tolkiens erfundenen Sprachen (üblich mit dem lateinischen Alphabet und diakritischen Zeichen geschrieben) in die Schriften, wie die Tengwar, Cirth oder Sarati, die er in seinen Werken erschaffen hat. Man kann sie auch für Sprachen und Schrifte unserer primären Welt weiter benutzen.
Mehr als eine herkömmliche Tengwar Umschreiber, Glǽmscribe ist eine allgemeine Umschriftengine, deren Verhalten von Modusdateien (in eigener Programmiersprache) bestimmt wird. Nach Tolkiens Wort heißt Modus ein besonderes System, das den Schriftzeichen phonetische Werte zuweist. Für Glǽmscribe ist es ein regeldefiniertes System, das die Beziehungen zwischen Eingabe (lateinische Buchstaben und Diakritika) und Ausgabe (Tolkiensche Schriftzeichen) beschreibt.
Share!
IPA
Audio
TTS Module is loading
tinco
xtinco
telco/a
telco/nasal/geminate
?
5
\
tinco
parma
calma
quesse
tinco
parma
calma
quesse
ando
umbar
anga
ungwe
ando
umbar
anga
ungwe
sule
formen
harma
hwesta
sule
formen
harma
hwesta
anto
ampa
anca
unque
anto
ampa
anca
unque
numen
malta
noldo
nwalme
numen
malta
noldo
nwalme
ore
vala
anna
vilya
ore
vala
anna
vilya
\
romen
arda
lambe
alda
romen
arda
lambe
alda
silme
silmen
esse
essen
silme
silmen
esse
essen
hyarmen
hwestas
yanta
ure
hyarmen
hwestas
yanta
ure
telco
ara
telco
ara
xtinco
xparma
xcalma
xquesse
xtinco
xparma
xcalma
xquesse
xando
xumbar
xunque
xungwe
xando
xumbar
xunque
xungwe
halla
vaia
osse
hwl
halla
vaia
osse
hwl
mh
mhb
hwbom
wbom
mh
mhb
hwbom
wbom
harmasilme
harmasilme
hwestatinco
hwestatinco
harmatinco
harmatinco
telco/a
telco/e
telco/i
telco/o
telco/u
a
e
i
o
u
telco/ee
telco/ii
telco/oo
telco/uu
ee
ii
oo
uu
telco/arev
telco/egrave
arev
egrave
telco/acirc
acirc
telco/breve
telco/labial
breve
labial
telco/a<
telco/e<
telco/i<
telco/o<
telco/u<
a<
e<
i<
o<
u<
telco/ee<
telco/ii<
ee<
ii<
telco/lsd
telco/thinnas
lsd
thinnas
parma/geminate
parma/nasal
parma/labial
parma/palatal
geminate
nasal
labial
palatal
parma/sarince
parma/arrince
sarince
arrince
,
.
...
::
....
.....
,
.
...
::
....
.....
?
!
~
?
!
~
«
»
(
)
$
«
»
(
)
$
≤
≥
≤
≥
1
2
3
4
5
6
1
2
3
4
5
6
7
8
9
10
11
12
7
8
9
10
11
12
0
1/lsd
0
lsd
Iä! Iä! Cthulhu naflfhtagn! Iä!
Text to speech modes activated!
Tengwar-Modus für Adûnaïsch, für Glǽmscrafu entwickelt. Abgeleitet vom allgemeinen Gebrauch des Dritten Zeitalters, von dem eine ausführliche Analyse auf Englisch von Måns Björkman Berg auf Amanyë Tenceli und eine kürzere auf Deutsch von Gernot Katzer vorliegen. Eigentümlich werden die prenasalisierten stimmhaften Plosiven nd, mb und ng durch die vierte Reihe der Tengwar (mit verlängertem Stamm und verdoppeltem Bogen) geschrieben.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Tengwar-Modus für die Schwarze Sprache, von der Inschrift des Einen Rings veranschaulicht. Eine besondere Verwendung des allgemeinen Gebrauchs des Dritten Zeitalters, von der eine ausführliche Analyse auf Englisch von Måns Björkman Berg auf Amanyë Tenceli vorliegt.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Phonemischer Cirth-Modus für Englisch. Er basiert auf J. R. R. Tolkiens Beschreibungen im Anhang E des Herrn der Ringe. Da die Rechtschreibung des Englischen auf die Aussprache nicht zuverlässig hinweist, beruht der Modus auf einer untergründigen phonemischen Repräsentation durch eine modifizierte Version der Sprachsynthese-Software eSpeak NG, mit Optionen, um verschiedene Sprechakzente aufzunehmen.
Wir haben die Gebrauchsanweisung noch nicht auf Deutsch übersetzt, so legen wir hier vorläufig die englische Fassung vor.
Introduction
This certh mode is largely inspired by the Angerthas Daeron system described by Tolkien in the Appendices of The Lord of the Rings. The mode that we present is therefore essentially phonemic with an additional phonetic layer to accommodate various pronunciations. It relies on our modified version of the text-to-speech engine eSpeak NG ; we will not repeat here the motivations and implications of this technical choice, but you can read more on that subject in the introduction of the English phonemic tengwa mode manual.
According to the Lord of the Rings appendix, the cirth underwent various adaptations during the history of Middle-Earth, from their invention by the Sindar during the First Age up to their use by the Dwarves to represent languages of Men during the Third Age. That late system, called Angerthas Erebor is briefly described in the Lord of the Rings as an adaptation of the Angerthas Moria by the Dwarves, which was itself borrowed and adapted from the Angerthas Daeron, a phonemic systematization of the cirth by Daeron. The most famous and longest examples of Angerthas Erebor we have from Tolkien's hand to transcribe English are the pages of the Book of Mazarbul, where we can observe that accordingly to his habits with tengwar, Tolkien made a mix of phonemic and orthographic choices. For example, the <a> letter would always be transcribed the same way, independently of its pronunciation (cf words like wall/taken/gate), the same occurs for <e> (we/they) except when it is used as a schwa (e.g taken) ; double vowel letters are often marked by doubling a part of the certh (e.g. pool/deep), and we can even notice that principle for consonants, like the <l> letter (e.g. wall). For an automatic tool like Glaemscribe, this mixed characterization make things really complex since the base representation is either purely orthographic, or phonetic (when provided by the espeak NG engine). It is the reason why we could simply not technically implement an Angerthas Erebor mode, and why we've fallen back to the old Angerthas Daeron system that we adapted and completed with our own choices. Missing runes are often taken from the Angerthas Erebor but will often have different values so one should be a bit careful not to be confused. It thus should be noted here that a lot of choices made for this mode are reconstructions or extrapolations, and although we tried our best to be close to Tolkien's spirit, this mode should not be regarded as strict tolkienian scholarship.
Caution: it is strongly advised to carefully check the transcription produced by this mode, because generating a phonemic representation of English from the written form is exceedingly complex and unexpected results may still happen despite our best efforts and those of eSpeak NG creators. In particular, fancy or non standard punctuation should be avoided and constituent parts of some compound words may require to be separated by a pipe | to be read correctly. Generally speaking, we advise you to document yourself about the tengwar, cirth or sarati before making use of a transcriber.
See also below Transcriber limits and useful precautions.
A page from the Book of Mazarbul, by J.R.R. Tolkien, source Tolkien Estate
Accents
Received Pronunciation (RP)
The so-called Received Pronunciation is the British English reference accent, generally taught abroad and recorded in dictionaries. It originates from the general pronunciation of the upper classes raised in public schools and does not relate to a particular region of Great Britain. It is the typical, and for a long time exclusive BBC accent (today the BBC features a greater variety of regional accents). It was codified by the phonetician Daniel Jones in his English Pronouncing Dictionary, published for the first time in 1917 and since then regularly updated (the 18th edition was published in 2011).
Over a century, usage has naturally changed somewhat and today´s RP is not entirely like the original. So we offer two varieties of RP:
a “traditional” RP, as it is still typically recorded in dictionaries. It uses the symbols of the International phonetic alphabet (IPA) selected in 1962 by Alfred C. Gimson (a student of Daniel Jones) in his Introduction to the Pronunciation of English. Apart from a few details, this was J. R. R. Tolkien´s usual pronunciation, as shown by Laurence Krieg in an article published in 1978 in An Introduction to Elvish. Today however, it can sound dated, reserved for certain classes and associated with higher age groups. This is typically what was referred to as The Queen's English under the reign of Elizabeth II.
a “contemporary” RP, with IPA symbols more in line with current usage.
In most instances, differences are a matter of phonetics (the physical reality of phonemes as articulatory and acoustic phenomena) and not of phonology (the system of mutual relationships between phonemes that determine their linguistic functioning). The tengwa/certh transcription operates at the phonological level and remains therefore unchanged. In a few cases however, the phonological system has really been affected by a substitution or merger of phonemes, and this ends up changing the tengwa/certh transcription.
General American (GA)
The so-called General American is the American English reference accent, generally taught abroad and recorded in dictionaries. It is actually a set of closely related accents widely distributed over the United States and regarded as relatively neutral, meaning that they are not readily associated with a specific region, social class or community.
Tolkienian (JRRT)
Or so-called Tolkienian accent has been specifically constructed for Glǽmscribe to get a tengwar/cirth representation as close as possible to J. R. R. Tolkien´s uses in our reference sample of phonemic modes. It is mostly based upon traditional RP but restores some etymological distinctions that were already lost but can be recovered from the orthography or other accents; in particular, it keeps the full etymological distribution of the /r/ phoneme. It has no current living equivalent but can be compared with J. R. R. Tolkien´s exalted pronunciation when he was reading the most heroic or epic parts of his own works, especially his poems, like in this extract of the Song of the Mounds of Mundburg:
Daniel Jones (1881–1967) aged 40.
Elliott and Fry, 1920 or 1921 - Wikimedia Commons.
Vowels
English accents differ the most in their vowel systems. In order to describe in a general way the correspondences between RP and GA, the phoneticist John C. Wells in 1982 defined 24 lexical sets grouping the words with the same correspondance in their stressed vowel, supplemented with 3 other sets for reduced vowels. This system was later extended to the description of other accents. It allows to define an abstract common base from which various accents can be deduced in eSpeak NG, and subsequently the various transcriptions in Glǽmscribe. It must be noted however that some correspondences are irregular and out of the lexical set system.
On the right side is a table of lexical sets used Glǽmscribe, their IPA transcription by eSpeak NG and their cirth transcription.
Monophthongs
Monophthongs are directly adapted from the Angerthas Daeron chart, by performing a canonical association based on vowel length and quality.
Diphthongs
The cirth that we use for diphthongs are often borrowed from the Angerthas Erebor, but may have different associated sounds since the Angerthas Erebor logic is orthographic while we try here to keep a phonemic logic in the graphical choice of the cirth. For example, the doubling of the bar for the c47 certh was used by Tolkien to represent a long /i:/ through the <ee> orthography while in our mode it will represent the /eɪ/ diphthong (considered as the combination /e/+/i/). Tolkien would even use the same certh for the same orthography leading to multiple diphthongs : cf the page 3 of the Book of Mazarbul where the same certh is used for <ea> in great and near.
U-Diphthongs
The /aʊ/, /əʊ/, /oʊ/ diphthongs use cirth borrowed from the Angerthas Erebor. The certh c45alt can be used for the vowel of the word goose, which is our extrapolation - the logic being that c45alt is visually a mix of c42 and c44 so that it offers a /uʊ/ diphthong-like transcription for /uː/.
I-Diphthongs
The /aɪ/ diphthong is borrowed from the Angerthas Erebor. Other i-diphthongs are extrapolations based on the use of the small c59 certh, which is normally used in the Angerthas Daeron to mark aspiration but finds no use in English. This idea is inspired by the construction of the ce4 certh used for /aɪ/ in the Angerthas Erebor, which is a mix of the c48 and c59 cirth. So :
c52alt for /ɔɪ/ is derived from c50 + c59
c47 for /eɪ/ is derived from c46 + c59
c39|c59 for /iː/ is derived from c39 + c59
Reduced vowels
Reduced vowels are treated a bit differently than in the tengwa mode, because cirth do not carry tehtar. It implies that reduced vowels always live separately, and if you could find empty carriers in the tengwa mode with the implicit schwa option on, the behaviour will be slightly different here.
First thing to note is, in the Angerthas Moria Tolkien would make a distinction between the reduced vowel /ʌ/ of the word strut and the other schwas by changing the orientation of the certh (c55 / c55alt vs c56 / c56alt). Since we already had a use for the c59 certh as the second element of i-diphthongs, we also propose to reuse this certh to make the distinction for the schwi.
Having the possibility of representing reduced vowels by a vertical barred certh or just simple accents, we thought we could build an interesting system to differentiate mandatory (with vertical barred cirth) and could-be-implicit schwas (with accents). If the implicit schwa option is on, the later ones will disappear, and another option will be available for choosing the representation of the remaining ones. That differentiation system can also be disabled.
Monophthongs
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
trap
tɹˈæp
8Rc1
tɹˈap
8Rc1
tɹˈæp
8Rc1
tɹˈæp
8Rc1
bath
bˈɑːθ
2v0
bˈɑːθ
2v0
bˈɑːθ
2v0
bˈæθ
2c0
palm
pˈɑːm
1v6
pˈɑːm
1v6
pˈɑːm
1v6
pˈɑːm
1v6
lot
lˈɒt
ab8
lˈɒt
ab8
lˈɒt
ab8
lˈɑːt
av8
cloth
klˈɒθ
eab0
klˈɒθ
eab0
klˈɒθ
eab0
klˈɔθ
eab0
thought
θˈɔːt
0n8
θˈɔːt
0n8
θˈɔːt
0n8
θˈɔːt
0n8
kit
kˈɪt
el8
kˈɪt
el8
kˈɪt
el8
kˈɪt
el8
dress
dɹˈɛs
9Rzf
dɹˈɛs
9Rzf
dɹˈɛs
9Rzf
dɹˈɛs
9Rzf
strut
stɹˈʌt
f8R?8
stɹˈʌt
f8R?8
stɹˈʌt
f8R?8
stɹˈʌt
f8R?8
foot
fˈʊt
3S8
fˈʊt
3S8
fˈʊt
3S8
fˈʊt
3S8
I-diphthongs
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
face
fˈeɪs
3xf
fˈeɪs
3xf
fˈeɪs
3xf
fˈeɪs
3xf
fleece
flˈiːs
3alVf
flˈiːs
3alVf
flˈiːs
3alVf
flˈiːs
3alVf
price
pɹˈaɪs
1R&f
pɹˈaɪs
1R&f
pɹˈaɪs
1R&f
pɹˈaɪs
1R&f
choice
tʃˈɔɪs
#<f
tʃˈɔɪs
#<f
tʃˈɔɪs
#<f
tʃˈɔɪs
#<f
U-diphthongs
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
goat
ɡˈoʊt
rk8
ɡˈəʊt
rK8
ɡˈəʊt
rK8
ɡˈoʊt
rk8
goose
ɡˈuːs
rDf
ɡˈuːs
rDf
ɡˈuːs
rDf
ɡˈuːs
rDf
mouth
mˈaʊθ
6*0
mˈaʊθ
6*0
mˈaʊθ
6*0
mˈaʊθ
6*0
cute
kjˈuːt
e;D8
kjˈuːt
e;D8
kjˈuːt
e;D8
kjˈuːt
e;D8
Pre-R vowels
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
nurse
nˈɜːɹs
@>Tf
nˈɜːs
@>Tf
nˈɜːs
@>Tf
nˈɜːɹs
@>Tf
start
stˈɑːɹt
f8vT8
stˈɑːt
f8v8
stˈɑːt
f8v8
stˈɑːɹt
f8vT8
north
nˈɔːɹθ
@nT0
nˈɔːθ
@n0
nˈɔːθ
@n0
nˈɔːɹθ
@nT0
force
fˈoːɹs
3kTf
fˈɔːs
3nf
fˈɔːs
3nf
fˈoːɹs
3kTf
near
nˈɪɹ
@lT
nˈiə
@l/
nˈiə
@l/
nˈɪɹ
@lT
square
skwˈɛɹ
feFzT
skwˈeə
feFz/
skwˈeə
feFz/
skwˈɛɹ
feFzT
poor
pˈʊɹ
1ST
pˈɔː
1n
pˈʊə
1S/
pˈʊɹ
1ST
Reduced vowels
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
comma
kˈɒmɐ
eb6/
kˈɒmə
eb6/
kˈɒmɐ
eb6/
kˈɑːmə
ev6/
roses
ɹˈoʊzᵻz
RkhVh
ɹˈəʊzɪz
RKhlh
ɹˈəʊzɪz
RKhlh
ɹˈoʊzᵻz
RkhVh
happy
hˈæpi
.c1l
hˈapi
.c1l
hˈæpɪ
.c1l
hˈæpi
.c1l
letter
lˈɛtɚ
az8>T
lˈɛtə
az8/
lˈɛtɐ
az8/
lˈɛɾɚ
az8>T
Consonants
Here is the table of cirth for the consonants. They closely follow the Angerthas Daeron chart.
The default certh c40 for the consonantal y is borrowed from the Angerthas Erebor. An option is available to keep the original c39 certh from the Angerthas Daeron but since it is also used for the standard i vowel, we preferred to maximize the cirth orthography by distinguishing both of them.
Prenasalization
When nasals precede consonants with the same point of articulation, they are marked with a circumflex accent (but you can use separate cirth).
Rhoticity
The /r/ phoneme varies a lot in English and is a chief distinguishing feature between its varieties. On the one hand, it is articulated in many ways; here the RP and GA accents agree to use an approximant [ɹ]. On the other hand, its distribution varies. In some varieties of English, called non-rhotic, the /r/ phoneme has been kept at the beginning of syllables only and lost at the end of syllables after affecting the previous vowel: RP is an example of a non-rhotic variety. Other varieties, called rhotic, keep the etymological distribution of /r/ including at the end of syllables: GA is an example of a rhotic variety.
J. R. R. Tolkien usually spoke a variety close to the RP of his time, non-rhotic with an approximant [ɹ]. Nevertheless, he might at time use rhotic pronunciations for stylistic effect, with more forceful articulations of /r/ such as the tap [ɾ] or the even stronger trill [r]. Laurence Krieg noted in 1978 already that the loftier the style of the text he was reading, the stronger rhoticity and more forceful articulation he resorted to. Here Tolkien was recreating phonetic features of earlier forms of English and bringing to the relevant fragments the glamour of antiquity. This can be regarded as a kind of “glorious archaism”.
In many non-rhotic accents, especially the RP, final /r/ is nevertheless re-established when the following word begins in a vowel: this is called a linking R. Compare for instance the contemporary RP pronunciation of Far West /fɑː wɛst/ and Far East /fɑːr‿ iːst/, your mouth /jɔː maʊθ/ and your eyes /jɔːr‿ aɪz/, for me /fɔː miː/ and for us /fɔːr‿ ʌs/, etc. This speech process is often extended to the insertion of /r/ between any word ending in /ə/, /ɪə/, /ɑː/ ou /ɔː/ and a following word beginning in a vowel, even if that /r/ is not warranted by etymology: this is then called an intrusive R. For instance, vanilla ice /vənɪlər‿ aɪs/ is then uttered like vanilla rice /vənɪlə ɹaɪs/. Both the linking and intrusive R are very common in RP, despite some speakers considering the intrusive R to be “incorrect” because it is absent from the spelling. J. R. R. Tolkien was using both and this habit could even surface in the pronunciation of his Elvish tongues: for istance, a distinct intrusive R can be heard between the first two words in his record of A Elbereth Gilthoniel:
The certh transcription remains unaffected by the purely phonetic variation between the various articulations of /r/ but is sensible to rhoticity. In rhotic accents, /r/ is represented by c29 at the beginning of syllables and by c30 at the end of syllables. In non-rhotic accents, two options allow to choose to represent the linking and intrusive R (independently of each other) by c30; this is the only case where c30 is used for /r/ in those accents. Finally, intrusive R is also available for the JRRT accent despite its rhotic foundation.
Transcription of WH
The digraph WH was long used in English to spell the cluster /hw/ or its evolution /ʍ/ (a voiceless counterpart to /w/). However, for most English speakers today /hw/ or /ʍ/ has merged with /w/: this is called the wine-whine merger after a pair of words that became homonyms by that change. Other homonymic pairs created therby are wail / whale, way / whey, wet / whet, wether / weather, witch / which, wight / white etc. The distinction is still found in Scotland, Ireland and some parts of the southern United States.
J. R. R. Tolkien usually did not made the distinction, but could reintroduce it when speaking in a more elevated style, like here in the Lament for the Rohirrim: For Sindarin, this sound is specifically referenced in the Angerthas Daeron chart in the Appendix E of the Lord of the Rings as /hw/ for the certh c5. The historical orthography of English can be relied upon (for once!) to reintroduce the distinction from the written form, and the transcriber offers this possibility as an option.
Important exception: /hw/ was early reduced to /h/ before a rounded vowel and this /h/ endures today (except in accents that regularly drop /h/), but the spelling as WH was not changed. Those WH standing for /h/ are transcribed in cirth with c54 according to their pronunciation. Notable relevant words are who, whom, whose, whole and whore.
Assimilation of N before C/K and G
In English, the letter N before the velar stops /k/ and /g/ (respectively written C/K and G) usually stand for the velar nasal /ŋ/. However, when a prefix ending in N is added to a stem beginning in /k/ or /g/, the pronunciation varies. In polished language and dictionary records, N stands for /n/ as it it was at word end, but in a more colloquial language the natural tendency to assimilate to /ŋ/ may run its course. This applies in particular to words with the following prefixes:
con-: e.g. conclude, concur, conglomerate, congratulate...
en-: e.g. encourage, enclose, engage, engrave...
in-: e.g. incarnate, income, inglorious, ingurgitate...
non-: e.g. nonclassical, nonconformist, nonguilty, nongrowth...
on-: e.g. oncoming, ongoing...
un-: e.g. unclean, unkind, ungodly, ungrateful...
Such cases being quite numerous and amenable to a general description, the transcriber offers an option “n of include/ingoing” to switch on or off the assimilation of /n/ to /ŋ/ before /k/ and /g/ in all those prefixes.
On the other hand, when a compound word brings /n/ into contact with /k/ or /g/ at the boundary of the two elements, it remains necessary to use the pipe | to prevent the assimilation of the nasal into /ŋ/. Examples: mankind, painkiller, vainglory, fangirl etc.
I
II
III
IV
1
c8
/t/
tooth
c1
/p/
peace
c13
/tʃ/
church
c18
/k/
cold
2
c9
/d/
day
c2
/b/
boat
c14
/dʒ/
judge
c19
/g/
good
3
c10
/θ/
thin
c3
/f/
foot
c15
/ʃ/
ship
c20
/x/
loch
4
c11
/ð/
this
c4
/v/
vest
c16
/ʒ/
vision
.:.
5
c12
/n/
night
c6
/m/
mouth
c17
/nj/
kenya
c22
/ŋ/
long
6
c30
/ɹ/
car
c44
/w/
warm
c40
/j/
young
.:.
7
c29
/r/
red
.:.
c31
/l/
light
.:.
8
c34
/s/
sand
c35
/s/ (alt)
sand
.:.
c36
/z/
zoo
9
c54
/h/
hot
c5
/ʍ/
white
.:.
.:.
Number representation
Quinary system
Tolkien never published structured information about any numeric system using cirth, and we are only left with a few number of characters used in the Book of Mazarbul sheets :
1
1
2
2
3
3
4
4
5
5
That information is really sparse ; we miss the zero and we do not know which base would be used or how the next digits would be layered. We propose, as an option, a quinary (base 5) numeral system based on those digits, by completing with the c37 certh for zero (since it had currently no use in our mode and because it feels very exotic visually).
Pentadic system
Alternatively, we decided to build our own numeric system which is thus of pure invention, inspired from the Scandinavian pentadic system :
c31|sdot
0
c10|sdot
1
c3|sdot
2
c4|sdot
3
c7|sdot
4
c39|sdot
5
c8|sdot
6
c1|sdot
7
c2|sdot
8
c6|sdot
9
It is a simple base 10 system, and the underlying logic in the choice of the characters is the following :
the vertical bar represents 5, and is the "center" digit
zero is a struck out 5
all left oriented characters are lower than five
all right oriented characters are higher than five
the digit is deduced from the number of additional strokes
additional strokes are added from top to bottom
This system is proposed by default.
Transcriber limits and useful precautions
Inflexibility
A transcriber mechanically processes relations between written form and pronunciation: the same input always yields the same output. But humans (and even elves) are more changeful. In speech, the same word can be uttered differently according to personal use, context, style etc. Tolkien’s tengwar or cirth orthography is of the same kind: like mediæval writing, it is somewhat flexible and disregards the modern requirement that a word should always be spelt the same way. It definitely follows transcriptional rules, but for the same case they may result in several solutions that can be selected piecemeal, more or less freely, without incurring a “spelling mistake”. Other factors can then be taken into account: a specific tradition, the available space, a greater or lesser requirement for clarity, æsthetic considerations...
By nature, Glǽmscribe is unable to emulate this flexibility. It can only be introduced by human intervention, either by altering the written input to achieve the desired result, or more radically by using the “raw tengwar” feature.
Words with multiple pronunciations
Certain words may be pronounced in more than one way even within the same accent. This is often indicative of a competition between an older traditional form and a newer spelling pronunciation. In RP, for instance:
either is mostly sounded /ˈaɪðə(r)/ but a minority of speakers say /ˈiːðə(r)/, which is the dominant pronunciation in American English.
forehead is traditionnally sounded /ˈfɒrɪd/ but the pronunciation /ˈfɔːhɛd/, remade from the spelling and the independent forms of the two elements of this compound, is now usual.
nephew is today most often sounded /ˈnɛfjuː/ but the traditional pronunciation /ˈnɛvjuː/ can still be heard.
often is traditionally sounded /ˈɒfən/ but /ˈɒftən/ is found as well, although some people regard it as less correct.
schedule can be sounded /ˈʃɛdjuːl/ or /ˈskɛdjuːl/, with the second form closer to American English. The historical pronunciation was /ˈsɛdjuːl/ but is now obsolete.
Proper names
Proper names are an especially tricky challenge for a transcriber: their pronunciation is even less predictable that common vocabulary, because they preserve many old, dialectal or originally foreign forms. They are frequently written in irregular or non standard ways and are easily reduced, distorted or reinterpreted. They can only be reliably processed by listing all unpredictable pronunciations, but they are so numerous that a comprehensive list is impossible. Here the quality of the transcriber depends upon the size of its index. Whereas Glǽmscribe correctly interprets Arkansas /ˈɑː(r)kənsɔː/, Chatham /ˈtʃætəm/, Des Moines /dəˈmɔɪn/, Vaughan /ˈvɔːn/ and Worcester /ˈwʊstə(r)/, it fails to pronounce Aldeburgh /ˈɔːlbərə/, Beaulieu /ˈbjuːli/, Frome /ˈfruːm/, Leominster /ˈlɛmstə(r)/, Swansea /ˈswɒnzi/, not to mention oddities like Cholmondeley /ˈtʃʌmli/, Featherstonhaugh /ˈfænʃɔː/, Milngavie /mʌlˈɡaɪ/, Ratlinghope /ˈrætʃʌp/ or Trottiscliffe /ˈtrɒzli/. There are many, many more: just ask this gentleman...
In practice, you must pay special attention to the transcription of proper names and be ready to correct it if necessary.
Non standard punctuation
It is strongly discouraged to enter non standard punctuation or use it in a fancy way, because eSpeak may then produce the full names of the punctuations as spoken aloud. What a pity it would be to request the transcription of Bastard from Mordor!!!*&% and end up with a “Bastard from Mordor ! exclamation asterisk and percent” tatoo on your right shoulder...
References
࿔Duddington, Jonathan, Dunn, Reece H. et al.
eSpeak NG.
Open source software (GPL 3.0).
🌍 GitHub.
࿔Björkman Berg, Måns.
Tengwar – English General Use.
🌍 Amanyë Tenceli.
࿔Wust, J. Mach.
A phonetic tehtar mode: a proposition based on material by J. R. R. Tolkien.
PDF.
2003.
12 p.
🌍 Phonetic Calligraphic.
࿔Mellonath Daeron - the language guild of the Forodrim.
The Mellonath Daeron Index of Certh Specimina (DCS).
🌍 Mellonath Daeron.
࿔Bador, Damien.
Les numéraux de Fëanor.
🌍 Tolkiendil.
࿔Coombes, Matthew D.
The Elvish writing systems of J. R. R. Tolkien.
United Kingdom: Independent Publishers Network, 2016.
293 p.
ISBN 978-1-78280-807-7.
࿔Krieg, Laurence J..
Tolkien´s pronunciation: some observations.
Reprint of the 1978 edition.
In: Allan, Jim (ed.). An Introduction to Elvish and to other tongues and proper names and writing systems of the Third Age of the Western Lands of Middle-earth as set forth in the published writings of Professor John Ronald Reuel Tolkien..
Hayes: Bran’s Head Books, 2003.
P. 152-159.
ISBN 2-910681-03-3.
࿔Jones, Daniel.
Cambridge English pronouncing dictionary.
Edited by Peter Roach, James Hartman and Jane Setter.
17th edition.
Cambridge: Cambridge University Press, 2006.
599 p.
ISBN 978-0-521-68086-8.
࿔Wells, John C.
Accents of English.
Cambridge: Cambridge University Press, 1982.
3 vol., 673 p.
ISBN 0-521-22919-7 (vol. 1), 0-521-24224-X (vol. 2), 0-521-24225-8 (vol .3).
🌍 John Wells’s phonetic blog.
࿔Lindsey, Geoff.
English after RP: standard British pronunciation today.
Cham (Switzerland): Palgrave Macmillan, 2019.
153 p.
ISBN 978-3-030-04356-8.
🌍 English Speech Services - Geoff Lindsey’s blog.
࿔Robinson, Jonnie.
Received Pronunciation. Received Pronunciation consonant sounds. Vowel sounds of Received Pronunciation. Received Pronunciation connected speech processes.
London: British Library, 2019.
🌍 British accents and dialects.
Phonemischer Tengwar-Modus für Englisch mit von Tehtar auf dem folgenden Konsonanten geschriebenen Vokalen. Er basiert auf dem Gebrauch in gezeigten Beispielen von J. R. R. Tolkien im späteren Lebens. Da die Rechtschreibung des Englischen auf die Aussprache nicht zuverlässig hinweist, beruht der Modus auf einer untergründigen phonemischen Repräsentation durch eine modifizierte Version der Sprachsynthese-Software eSpeak NG, mit Optionen, um verschiedene Sprechakzente aufzunehmen.
Die Gebrauchsanweisung wird noch auf Deutsch übersetzt, so legen wir hier vorläufig die englische Fassung vor.
Introduction
Whereas the regular spelling of Elvish languages in Latin letters is easily amenable to automatic transcription, not all natural languages are that straightforward, especially English. English is endowed with a highly complex set of relations between its phonemes and written form and includes a wealth of local accents. The same string of letters can be pronounced differently according to etymology, word structure, grammatical context and many other factors. Conversely, one same sound can often be written in many different ways. That is why Glǽmscribe was so long to develop a much awaited mode: phonemic English. We wanted to present more than just a makeshift mode and back it up with sound linguistics (although perfection cannot be achieved in that area). This mode relies upon the speech synthesis software eSpeak NG that we customized for tengwa transcription. We would here like to acknowledge Didier Willis, because Glaemscribe was born in the will to technically realize an idea of his own which was to use espeak to perform sarati transcription from written english, which is now very close to hand.
Admittedly, J. R. R. Tolkien’s customary high variability on those topics is especially prevalent when writing English in tengwar. On this favorite playground of his, Tolkien took great pleasure emphasizing at times current pronunciation, at times language history. His variations also betoken waverings between his concern for consistency and his æsthetic fantasy, and like his whole linguistic invention are driven by artistic desire at the heart of his choices. His personal pronunciation and linguistic perception are therefore vital influences.
Nevertheless, automatic transcription is inherently a process of regularization. As we wanted to avoid erasing thereby the richness of Tolkien’s variations, we needed to work from an upstream representation of English featuring both regularity and maximal inclusivity, with full information on the language’s phonetics and phonemics. It turns out that those requirements are precisely addressed in speech synthesis. Speech synthesis reconstructs a phonemic representation from the writing form to deduce various local pronunciations of a language. We therefore started from the eSpeak NG engine but modified the phonetization layer - the phonetic realization and transcription in the International phonetic alphabet (IPA) - so as to preserve as much information as possible. This “augmented” IPA representation is then processed into tengwar. The result depends upon the selected pronunciation (four accents are available) and can be checked by ticking the “IPA” box on the user interface; a speech synthesis is also generated and can be listened to by ticking the “Audio” box. Since the speech synthesis engine is loaded and run by your browser, the transcription is more complex and therefore requires a significantly longer computing time than for other modes, so it can take a few seconds to be displayed.
The mode that we present is therefore essentially phonemic with an additional phonetic layer to accommodate various pronunciations. It is based on attested uses in samples by Tolkien in his later life, supplemented by our deductions and choices in cases not found in that corpus. Vowels are written with tehtar set on the tengwa representing the following consonant, according to his dominant (but not constant!) use. Many options (detailed below) are available, either to convey Tolkien’s variations or because we found them relevant to our approach.
It should be noted that this phonemic mode with tehtar for vowels is neither the only one nor even the best attested of the English modes created by J. R. R. Tolkien. More often actually, he made use of modes based on spelling rather than pronunciation, and more than everything of mixed approaches (which are exceedingly difficult to program!). In the early 1930s he had also developed a phonemic mode in the then current form of the tengwar, described in Parma Eldalamberon n° 20; however, as it follows partly different principles (for instance, vowels are mainly written in tengwar rather than represented by tehtar) it has not considered here and shall get its own Glǽmscribe mode.
Caution: it is strongly advised to carefully check the transcription produced by this mode, because generating a phonemic representation of English from the written form is exceedingly complex and unexpected results may still happen despite our best efforts and those of eSpeak NG creators. In particular, fancy or non standard punctuation should be avoided and constituent parts of some compound words may require to be separated by a pipe | to be read correctly. Generally speaking, we advise you to document yourself about the tengwar, cirth or sarati before making use of a transcriber.
See also below Transcriber limits and useful precautions.
The so-called Received Pronunciation is the British English reference accent, generally taught abroad and recorded in dictionaries. It originates from the general pronunciation of the upper classes raised in public schools and does not relate to a particular region of Great Britain. It is the typical, and for a long time exclusive BBC accent (today the BBC features a greater variety of regional accents). It was codified by the phonetician Daniel Jones in his English Pronouncing Dictionary, published for the first time in 1917 and since then regularly updated (the 18th edition was published in 2011).
Over a century, usage has naturally changed somewhat and today´s RP is not entirely like the original. So we offer two varieties of RP:
a “traditional” RP, as it is still typically recorded in dictionaries. It uses the symbols of the International phonetic alphabet (IPA) selected in 1962 by Alfred C. Gimson (a student of Daniel Jones) in his Introduction to the Pronunciation of English. Apart from a few details, this was J. R. R. Tolkien´s usual pronunciation, as shown by Laurence Krieg in an article published in 1978 in An Introduction to Elvish. Today however, it can sound dated, reserved for certain classes and associated with higher age groups. This is typically what was referred to as The Queen's English under the reign of Elizabeth II.
a “contemporary” RP, with IPA symbols more in line with current usage.
In most instances, differences are a matter of phonetics (the physical reality of phonemes as articulatory and acoustic phenomena) and not of phonology (the system of mutual relationships between phonemes that determine their linguistic functioning). The tengwa/certh transcription operates at the phonological level and remains therefore unchanged. In a few cases however, the phonological system has really been affected by a substitution or merger of phonemes, and this ends up changing the tengwa/certh transcription.
General American (GA)
The so-called General American is the American English reference accent, generally taught abroad and recorded in dictionaries. It is actually a set of closely related accents widely distributed over the United States and regarded as relatively neutral, meaning that they are not readily associated with a specific region, social class or community.
Tolkienian (JRRT)
Or so-called Tolkienian accent has been specifically constructed for Glǽmscribe to get a tengwar/cirth representation as close as possible to J. R. R. Tolkien´s uses in our reference sample of phonemic modes. It is mostly based upon traditional RP but restores some etymological distinctions that were already lost but can be recovered from the orthography or other accents; in particular, it keeps the full etymological distribution of the /r/ phoneme. It has no current living equivalent but can be compared with J. R. R. Tolkien´s exalted pronunciation when he was reading the most heroic or epic parts of his own works, especially his poems, like in this extract of the Song of the Mounds of Mundburg:
Queen Elizabeth II, 1952, Dorothy Wilding.
Source : The Postal Museum
Vowels
English accents differ the most in their vowel systems. In order to describe in a general way the correspondences between RP and GA, the phoneticist John C. Wells in 1982 defined 24 lexical sets grouping the words with the same correspondance in their stressed vowel, supplemented with 3 other sets for reduced vowels. This system was later extended to the description of other accents. It allows to define an abstract common base from which various accents can be deduced in eSpeak NG, and subsequently the various transcriptions in Glǽmscribe. It must be noted however that some correspondences are irregular and out of the lexical set system.
On the right side is a table of lexical sets used Glǽmscribe, their IPA transcription by eSpeak NG and their tengwa transcription.
The long vowels /ɑː/ (PALM) and /ɔː/ (THOUGHT) can be represented by a tehta on the following vowel (doubled for THOUGHT) or on a long carrier.
The vowels /iː/ (FLEECE) and /uː/ (GOOSE) are traditionally described as long vowels but are phonetically slightly diphthongized in RP and GA. They phonologically pattern with diphthongs and have the same distribution, and some linguists accordingly regard them as such. Tolkien knew that and sometimes spelt those vowels in tengwar with diphthong-like equivalents of the sequences /ij/ and /uw/. We offer three options to represent those vowels: with a double tehta, with a tehta on a long carrier or like diphthongs.
The vowel /ʌ/ (STRUT) is actually prononced in many different ways. Some speakers do not sound it apart from schwa, the reduced vowel of the COMMA lexical set: this is accordingly called the strut-comma merger. We offer three options to represent that vowel: with an understroke, a grave accent or an underdot like schwa to show the merger.
The vowel CUTE was once a diphthong /iu/. Some varieties of English (especially Welsh English) still preserve it today, but most (including RP and GA) have shifted it to a /juː/ sequence. Later, /j/ disappeared in some contexts (more numerous in GA than in RP) and thus triggered a merger with /uː/ of GOOSE. We offer two options to represent the CUTE vowel : like a sequence, with yanta standing for /j/ followed by whathever selected representation of /uː/ of GOOSE, or like the diphtong it once was.
Finally, the meanings of the curl-tehtar can be switched. By default, downward curls stand for O-like vowels like English /ɔ/ of CLOTH (single curl) and /ɔː/ of THOUGHT (double curl or single curl on long carrier); upward curls stand for U-like vowels like English /ʊ/ of FOOT (single ccurl) and /uː/ of GOOSE (double curl or single curl on long carrier or on vala). However, Tolkien sometimes made the converse choice, albeit more rarely, and that variation is attested in his English modes. Therefore the trancriber has an option to set the meaning of the curls.
Optional distinctions
Within the RP and GA are variations due to ongoing phonetic evolutions, typically completed for the younger but not for the older speakers, who often keep the former pronunciation still common in their youth. We offer options for two of those evolutions.
hyarmen/ore/o/silme/,/hyarmen/ore/oo/silme
HORSE · HOARSE
Horse-hoarse merger: this is a merger into the NORTH lexical set of the FORCE lexical set, making the words horse and hoarse homonyms. This merger is completed in RP (although the distinction was still done in the first editions of the English Pronouncing Dictionary) and the option is not available. The majority of GA speakers also have it but some still retain the distinction, so the option is available. It is also for the JRRT accent.
quesse/tinco/o/,/quesse/tinco/oo
COT · CAUGHT
Cot-caught merger: this is a merger into the LOT lexical set of the THOUGHT lexical set, making the works cot and caught homonyms. It is currently progressing in GA but still varies from speaker to speaker, so the option is available. The RP and JRRT accents maintain the distinction so the option is not available.
Monophthongs
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
trap
tɹˈæp
tɹˈæp
tɹˈap
tɹˈæp
bath
bˈɑːθ
bˈɑːθ
bˈɑːθ
bˈæθ
palm
pˈɑːm
pˈɑːm
pˈɑːm
pˈɑːm
lot
lˈɒt
lˈɒt
lˈɒt
lˈɑːt
cloth
klˈɒθ
klˈɒθ
klˈɒθ
klˈɔθ
thought
θˈɔːt
θˈɔːt
θˈɔːt
θˈɔːt
kit
kˈɪt
kˈɪt
kˈɪt
kˈɪt
dress
dɹˈɛs
dɹˈɛs
dɹˈɛs
dɹˈɛs
strut
stɹˈʌt
stɹˈʌt
stɹˈʌt
stɹˈʌt
foot
fˈʊt
fˈʊt
fˈʊt
fˈʊt
I-diphthongs
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
face
fˈeɪs
fˈeɪs
fˈeɪs
fˈeɪs
fleece
flˈiːs
flˈiːs
flˈiːs
flˈiːs
price
pɹˈaɪs
pɹˈaɪs
pɹˈaɪs
pɹˈaɪs
choice
tʃˈɔɪs
tʃˈɔɪs
tʃˈɔɪs
tʃˈɔɪs
U-diphthongs
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
goat
ɡˈoʊt
ɡˈəʊt
ɡˈəʊt
ɡˈoʊt
goose
ɡˈuːs
ɡˈuːs
ɡˈuːs
ɡˈuːs
mouth
mˈaʊθ
mˈaʊθ
mˈaʊθ
mˈaʊθ
cute
kjˈuːt
kjˈuːt
kjˈuːt
kjˈuːt
Pre-R vowels
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
nurse
nˈɜːɹs
nˈɜːs
nˈɜːs
nˈɜːɹs
start
stˈɑːɹt
stˈɑːt
stˈɑːt
stˈɑːɹt
north
nˈɔːɹθ
nˈɔːθ
nˈɔːθ
nˈɔːɹθ
force
fˈoːɹs
fˈɔːs
fˈɔːs
fˈoːɹs
near
nˈɪɹ
nˈiə
nˈiə
nˈɪɹ
square
skwˈɛɹ
skwˈeə
skwˈeə
skwˈɛɹ
poor
pˈʊɹ
pˈʊə
pˈɔː
pˈʊɹ
cure
kjˈʊɹ
kjˈʊə
kjˈɔː
kjˈʊɹ
Reduced vowels
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
comma
kˈɒmɐ
kˈɒmɐ
kˈɒmə
kˈɑːmə
roses
ɹˈoʊzᵻz
ɹˈəʊzɪz
ɹˈəʊzɪz
ɹˈoʊzᵻz
happy
hˈæpi
hˈæpɪ
hˈapi
hˈæpi
letter
lˈɛtɚ
lˈɛtɐ
lˈɛtə
lˈɛɾɚ
Reduced vowels
English has two main reduced vowels:
schwa, a central mid vowel transcribed [ə] (or [ɐ] for a more open variety); in the table it is represented by the COMMA lexical set;
a closer vowel sometimes called “schwi”, traditionally transcribed [ɪ] in Great Britain and [ᵻ] in America; in the table it is represented by the ROSES lexical set.
Their repartition is mostly conditioned by the phonetic environment, but is not fully predictable for some speakers and can then used to distinguish words: for instance addition / edition, Lennon / Lenin, Rosa’s / roses. This makes them two distinct phonemes; this is generally the case in RP. Other speakers do not hear the difference or have it wholly determined by the environment, making them allophones of a single phoneme; this is often (but not always) the case in GA. The transcriber offers two options to adjust to represented of those reduced vowels:
on the one hand, schwi can be represented either like schwa /ə/ (to show the merger) or like /ɪ/ of KIT (to show the distinction);
on the other hand, schwa can either be represented explicitly by an underdot or remain implicit (like a in some Quenya modes). Implicit schwa still requires to mark its presence at the word beginning and end, because then it is not predictable in in those positions: this is done with a short carrier without a tehta. The word America exemplifies how schwa is marked in both positions: explicit malta/i</romen/e/quesse/i/telco/i< or implicit telco/malta/romen/e/quesse/i/telco. Reduced vowels medially can usually be deduced from the word’s structure and knowledge of the language; leaving them out of writing may still cause some rare ambiguities (like quite /kwaɪt/ vs. quiet) but the context should make it clear.
The GA accent also features a retroflex schwa [ɚ], which is the phonetic realization of the phoneme sequence /ər/ and is represented as such the tengwa transcription. Our contructed JRRT accent includes it as well.
English often features final /i/, generally written -y like in happy, easy, holy etc. The traditional RP sound for this vowel is lax and open and identifies with /ɪ/ of KIT; it has become tenser and closer in contemporary RP, a change called happy tensing by phoneticists. GA also uses a tense /i/. This variation shows in the IPA transcription but does not change the tengwa transcription.
The preposition to is a special case. Its unstressed vowel /ʊ/ is commonly reduced to schwa /ə/ before a consonant but is kept before a vowel or a pause. Tolkien disregarded this reduction when he wrote English in tengwar, but an option allows to take it into account and write to with schwa when relevant, including in compound words: into, unto, today, tonight, together, togetherhood and togetherness, toward and towards.
Reduced vowels
J.R.R.T.
R.P. (anc.)
R.P. (mod.)
U.S.
comma
kˈɒmɐ
kˈɒmɐ
kˈɒmə
kˈɑːmə
roses
ɹˈoʊzᵻz
ɹˈəʊzɪz
ɹˈəʊzɪz
ɹˈoʊzᵻz
happy
hˈæpi
hˈæpɪ
hˈapi
hˈæpi
letter
lˈɛtɚ
lˈɛtɐ
lˈɛtə
lˈɛɾɚ
Consonants
English consonants are more easily represented than vowels. The main difficulty is the /r/ phoneme. Aside is a table of English consonants with the IPA transcription by eSpeak NG and their tengwa transcription by Glǽmscribe.
Modifications by tehtar
J. R. R. Tolkien regularly used tehtar as shorthands for common consonant clusters. This mode allows to switch them on and off by a set of options. When tehtar are on, one may still wish to write certain consonant clusters in full, especially at the boundary between a prefix and a stem or between elements of a compound word, in order to emphasize the etymological structure. The pipe | is then to be used to keep elements separate.
tinco/nasal
Prenasalization: a nengwetehta similar to a tilde or bar over a tengwar means that the consonant is preceded by a nasal at the same place of articulation. Examples: campquesse/parma/nasal/arev, paintparma/anna/e/tinco/nasal, finchformen/calma/nasal/i, inkquesse/nasal/i, ambushumbar/nasal/arev/harma/u, landlambe/ando/nasal/arev, singesilme/anga/nasal/i, fingerformen/anga/nasal/i/ore etc. Two options are offered, on the one hand to choose whether prenasalization will or will not be marked by nengwetehtar, on the other hand to select whether those will be tildes or bars.
tinco/labial
Trailing sibilant: a swash (called sa-rince in Quenya) attached to a tengwa means that the consonant is followed by /s/ or /z/. It is much used at the end of words for -s marking the plural of nouns and the 3rd person singular of verbs in the present simple. Examples: potsparma/tinco/o/sarince, bondsumbar/ando/nasal/o/sarince, reefsromen/formen/ii/sarince, liveslambe/anna/a/anto/sarince, lambslambe/malta/a/sarince, bellsumbar/lambe/e/sarince. A swash to the left is used for the clusters /ks/, /gz/ and /ŋz/. Examples : axequesse/sarince/arev, exitungwe/sarince/e/tinco/i, ringsromen/nwalme/i/sarince. Options allow to switch sa-rince on and off everywhere or to use it at the end of words only.
Rhoticity
The /r/ phoneme varies a lot in English and is a chief distinguishing feature between its varieties. On the one hand, it is articulated in many ways; here the RP and GA accents agree to use an approximant [ɹ]. On the other hand, its distribution varies. In some varieties of English, called non-rhotic, the /r/ phoneme has been kept at the beginning of syllables only and lost at the end of syllables after affecting the previous vowel: RP is an example of a non-rhotic variety. Other varieties, called rhotic, keep the etymological distribution of /r/ including at the end of syllables: GA is an example of a rhotic variety.
J. R. R. Tolkien usually spoke a variety close to the RP of his time, non-rhotic with an approximant [ɹ]. Nevertheless, he might at time use rhotic pronunciations for stylistic effect, with more forceful articulations of /r/ such as the tap [ɾ] or the even stronger trill [r]. Laurence Krieg noted in 1978 already that the loftier the style of the text he was reading, the stronger rhoticity and more forceful articulation he resorted to. Here Tolkien was recreating phonetic features of earlier forms of English and bringing to the relevant fragments the glamour of antiquity. This can be regarded as a kind of “glorious archaism”.
In many non-rhotic accents, especially the RP, final /r/ is nevertheless re-established when the following word begins in a vowel: this is called a linking R. Compare for instance the contemporary RP pronunciation of Far West /fɑː wɛst/ and Far East /fɑːr‿ iːst/, your mouth /jɔː maʊθ/ and your eyes /jɔːr‿ aɪz/, for me /fɔː miː/ and for us /fɔːr‿ ʌs/, etc. This speech process is often extended to the insertion of /r/ between any word ending in /ə/, /ɪə/, /ɑː/ ou /ɔː/ and a following word beginning in a vowel, even if that /r/ is not warranted by etymology: this is then called an intrusive R. For instance, vanilla ice /vənɪlər‿ aɪs/ is then uttered like vanilla rice /vənɪlə ɹaɪs/. Both the linking and intrusive R are very common in RP, despite some speakers considering the intrusive R to be “incorrect” because it is absent from the spelling. J. R. R. Tolkien was using both and this habit could even surface in the pronunciation of his Elvish tongues: for istance, a distinct intrusive R can be heard between the first two words in his record of A Elbereth Gilthoniel:
The tengwa transcription remains unaffected by the purely phonetic variation between the various articulations of /r/ but is sensible to rhoticity. In rhotic accents, /r/ is represented by rómenromen at the beginning of syllables and by óreore at the end of syllables. In non-rhotic accents, two options allow to choose to represent the linking and intrusive R (independently of each other) by óre; this is the only case where óre is used for /r/ in those accents. Finally, intrusive R is also avaiblable for the JRRT accent despite its rhotic foundation.
Transcription of WH
The digraph WH was long used in English to spell the cluster /hw/ or its evolution /ʍ/ (a voiceless counterpart to /w/). However, for most English speakers today /hw/ or /ʍ/ has merged with /w/: this is called the wine-whine merger after a pair of words that became homonyms by that change. Other homonymic pairs created therby are wail / whale, way / whey, wet / whet, wether / weather, witch / which, wight / white etc. The distinction is still found in Scotland, Ireland and some parts of the southern United States.
J. R. R. Tolkien usually did not made the distinction, but could reintroduce it when speaking in a more elevated style, like here in the Lament for the Rohirrim: When writing English in tengwar he strictly upheld it, spelling /w/ with valavala and /hw/ or /ʍ/ with hwesta sindarinwahwestas. The historical orthography of English can be relied upon (for once!) to reintroduce the distinction from the written form, and the transcriber offers this possibility as an option.
Important exception: /hw/ was early reduced to /h/ before a rounded vowel and this /h/ endures today (except in accents that regularly drop /h/), but the spelling as WH was not changed. Those WH standing for /h/ are transcribed in tengwar with hyarmenhyarmen according to their pronunciation. Notable relevant words are who, whom, whose, whole and whore.
Assimilation of N before C/K and G
In English, the letter N before the velar stops /k/ and /g/ (respectively written C/K and G) usually stand for the velar nasal /ŋ/. However, when a prefix ending in N is added to a stem beginning in /k/ or /g/, the pronunciation varies. In polished language and dictionary records, N stands for /n/ as it it was at word end, but in a more colloquial language the natural tendency to assimilate to /ŋ/ may run its course. This applies in particular to words with the following prefixes:
con-: e.g. conclude, concur, conglomerate, congratulate...
en-: e.g. encourage, enclose, engage, engrave...
in-: e.g. incarnate, income, inglorious, ingurgitate...
non-: e.g. nonclassical, nonconformist, nonguilty, nongrowth...
on-: e.g. oncoming, ongoing...
un-: e.g. unclean, unkind, ungodly, ungrateful...
Such cases being quite numerous and amenable to a general description, the transcriber offers an option “n of include/ingoing” to switch on or off the assimilation of /n/ to /ŋ/ before /k/ and /g/ in all those prefixes.
On the other hand, when a compound word brings /n/ into contact with /k/ or /g/ at the boundary of the two elements, it remains necessary to use the pipe | to prevent the assimilation of the nasal into /ŋ/. Examples: mankind, painkiller, vainglory, fangirl etc.
I
II
III
IV
1
tinco
/t/
tooth
parma
/p/
peace
calma
/tʃ/
church
quesse
/k/
cold
2
ando
/d/
day
umbar
/b/
boat
anga
/dʒ/
judge
ungwe
/g/
good
3
sule
/θ/
thin
formen
/f/
foot
aha
/ʃ/
ship
hwesta
/x/
loch
4
anto
/ð/
this
ampa
/v/
vest
anca
/ʒ/
vision
....
5
numen
/n/
night
malta
/m/
mouth
noldo
/nj/
kenya
nwalme
/ŋ/
long
6
ore
/ɹ/
car
vala
/w/
warm
anna
/j/
young
....
7
romen
/r/
red
....
lambe
/l/
light
....
8
silme
/s/
sand
silmen
/s/
face
esse
/z/
zoo
essen
/z/
keys
9
hyarmen
/h/
hot
hwestas
/ʍ/
white
....
....
Shorthands
xando/,/xumbar/,/xumbar/geminate
THE · OF · OF THE
When writing English in tengwar, J. R. R. Tolkien usually used shorthands based on extended tengwar forms to spell the word the, of and the combination of the. The tranxriber uses them by default but they can be switched on and off by way of an option.
Number representation
Number representation in tengwar is mainly known by n° 13 of the journal Quettar, issued in February 1982. Elvish numbering concurrently used the decimal system (base 10) and the duodecimal system (base 12), and numbers could accordingly be represented in the one or the other. The digits were the following; those for 10 and 11 were by nature used in base 12 only, and there is also a specail sign for the dozen, elicited in Glǽmscribe by writing {{12}}.
0
0
1
1
2
2
3
3
4
4
5
5
6
6
7
7
8
8
9
9
10
10
11
11
12
12
Positional notation is used, written from the left to the right, but conversely to our system starts from the smallest powers forwards to the greatest. Conseuquently, in the decimal system, unit are first written, then tens, then hundreds, then thousands etc. In the duodecimal system, units are first written, then dozens, then grosses (a gross = decimal 144), then great grosses (a great gross = decimal 1728) etc.
Usual order
Elvish order
base 10 144
1/4/4
4/4/1
base 12 100
1/0/0
0/0/1
Glǽmscribe keeps by default our usual order starting from the greatest powers, but allows to switch to the Elvish order starting from the smallest powers by ticking the box “Reverse digit order in numbers”.
Numbers must be entered in Glǽmscribe in base 10, but the result in tengwar can optionally be displayed in base 10 or in base 12. In combination with the two digit orders, this makes four possible representations of a given number.
Raw tengwar usage
Like all other tengwar modes, this mode handles the “raw tengwar” feature, which allows the straightforward spelling of a tengwar series to be kept unmodified in transcription – which can be useful to incorporate some tengwar text that does not fit into the mode’s context. For more information, unfold the manual with the romen/ara/o button on the top right of the interface.
Transcriber limits and useful precautions
Inflexibility
A transcriber mechanically processes relations between written form and pronunciation: the same input always yields the same output. But humans (and even elves) are more changeful. In speech, the same word can be uttered differently according to personal use, context, style etc. Tolkien’s tengwar or cirth orthography is of the same kind: like mediæval writing, it is somewhat flexible and disregards the modern requirement that a word should always be spelt the same way. It definitely follows transcriptional rules, but for the same case they may result in several solutions that can be selected piecemeal, more or less freely, without incurring a “spelling mistake”. Other factors can then be taken into account: a specific tradition, the available space, a greater or lesser requirement for clarity, æsthetic considerations...
By nature, Glǽmscribe is unable to emulate this flexibility. It can only be introduced by human intervention, either by altering the written input to achieve the desired result, or more radically by using the “raw tengwar” feature.
Words with multiple pronunciations
Certain words may be pronounced in more than one way even within the same accent. This is often indicative of a competition between an older traditional form and a newer spelling pronunciation. In RP, for instance:
either is mostly sounded /ˈaɪðə(r)/ but a minority of speakers say /ˈiːðə(r)/, which is the dominant pronunciation in American English.
forehead is traditionnally sounded /ˈfɒrɪd/ but the pronunciation /ˈfɔːhɛd/, remade from the spelling and the independent forms of the two elements of this compound, is now usual.
nephew is today most often sounded /ˈnɛfjuː/ but the traditional pronunciation /ˈnɛvjuː/ can still be heard.
often is traditionally sounded /ˈɒfən/ but /ˈɒftən/ is found as well, although some people regard it as less correct.
schedule can be sounded /ˈʃɛdjuːl/ or /ˈskɛdjuːl/, with the second form closer to American English. The historical pronunciation was /ˈsɛdjuːl/ but is now obsolete.
Proper names
Proper names are an especially tricky challenge for a transcriber: their pronunciation is even less predictable that common vocabulary, because they preserve many old, dialectal or originally foreign forms. They are frequently written in irregular or non standard ways and are easily reduced, distorted or reinterpreted. They can only be reliably processed by listing all unpredictable pronunciations, but they are so numerous that a comprehensive list is impossible. Here the quality of the transcriber depends upon the size of its index. Whereas Glǽmscribe correctly interprets Arkansas /ˈɑː(r)kənsɔː/, Chatham /ˈtʃætəm/, Des Moines /dəˈmɔɪn/, Vaughan /ˈvɔːn/ and Worcester /ˈwʊstə(r)/, it fails to pronounce Aldeburgh /ˈɔːlbərə/, Beaulieu /ˈbjuːli/, Frome /ˈfruːm/, Leominster /ˈlɛmstə(r)/, Swansea /ˈswɒnzi/, not to mention oddities like Cholmondeley /ˈtʃʌmli/, Featherstonhaugh /ˈfænʃɔː/, Milngavie /mʌlˈɡaɪ/, Ratlinghope /ˈrætʃʌp/ or Trottiscliffe /ˈtrɒzli/. There are many, many more: just ask this gentleman...
In practice, you must pay special attention to the transcription of proper names and be ready to correct it if necessary.
Non standard punctuation
It is strongly discouraged to enter non standard punctuation or use it in a fancy way, because eSpeak may then produce the full names of the punctuations as spoken aloud. What a pity it would be to request the transcription of Bastard from Mordor!!!*&% and end up with a “Bastard from Mordor ! exclamation asterisk and percent” tatoo on your right shoulder...
References
࿔Duddington, Jonathan, Dunn, Reece H. et al.
eSpeak NG.
Open source software (GPL 3.0).
🌍 GitHub.
࿔Björkman Berg, Måns.
Tengwar – English General Use.
🌍 Amanyë Tenceli.
࿔Wust, J. Mach.
A phonetic tehtar mode: a proposition based on material by J. R. R. Tolkien.
PDF.
2003.
12 p.
🌍 Phonetic Calligraphic.
࿔Mellonath Daeron - the language guild of the Forodrim.
The Mellonath Daeron Index of Tengwa Specimina (DTS).
🌍 Mellonath Daeron.
࿔Bador, Damien.
Les numéraux de Fëanor.
🌍 Tolkiendil.
࿔Coombes, Matthew D.
The Elvish writing systems of J. R. R. Tolkien.
United Kingdom: Independent Publishers Network, 2016.
293 p.
ISBN 978-1-78280-807-7.
࿔Krieg, Laurence J..
Tolkien´s pronunciation: some observations.
Reprint of the 1978 edition.
In: Allan, Jim (ed.). An Introduction to Elvish and to other tongues and proper names and writing systems of the Third Age of the Western Lands of Middle-earth as set forth in the published writings of Professor John Ronald Reuel Tolkien..
Hayes: Bran’s Head Books, 2003.
P. 152-159.
ISBN 2-910681-03-3.
࿔Jones, Daniel.
Cambridge English pronouncing dictionary.
Edited by Peter Roach, James Hartman and Jane Setter.
17th edition.
Cambridge: Cambridge University Press, 2006.
599 p.
ISBN 978-0-521-68086-8.
࿔Wells, John C.
Accents of English.
Cambridge: Cambridge University Press, 1982.
3 vol., 673 p.
ISBN 0-521-22919-7 (vol. 1), 0-521-24224-X (vol. 2), 0-521-24225-8 (vol .3).
🌍 John Wells’s phonetic blog.
࿔Lindsey, Geoff.
English after RP: standard British pronunciation today.
Cham (Switzerland): Palgrave Macmillan, 2019.
153 p.
ISBN 978-3-030-04356-8.
🌍 English Speech Services - Geoff Lindsey’s blog.
࿔Robinson, Jonnie.
Received Pronunciation. Received Pronunciation consonant sounds. Vowel sounds of Received Pronunciation. Received Pronunciation connected speech processes.
London: British Library, 2019.
🌍 British accents and dialects.
Modus zum Übertragen des Gotischen aus seiner üblichen Translitteration ins von Wulfila erfundene gotische Alphabet.
Experimenteller Modus zur Transkription des Japanischen. Dieser Modus unterstützt die Hiragana, die Katakana und eine sehr kleine Veränderung des Hepburn-Transkriptionssystems. Ein oder zwei Disambiguierungstricks muss man beachten, um diesen Modus optimal zu gebrauchen: siehe die folgende Gebrauchsanweisung (zur Zeit nur auf Englisch und Französisch verfügbar).
Danke schön Toshi Omagari für die wertvollen Ratschläge!
Wir haben die Gebrauchsanweisung noch nicht auf Deutsch übersetzt, so legen wir hier vorläufig die englische Fassung vor.
Introduction
By devising a tengwar mode for the transcription of Japanese, we want to present an original, totally unprecedented work. It is likely that Tolkien’s knowledge of languages from Eastern Asia was extremely limited - which gives to this choice, within an Elvish and Tolkienian referential, an undeniable exotic character. And yet, within the modern collective imagination, bridging Tolkien’s legendarium and certain universes arisen from Japanese culture does not appear so strange.
What Tolkien reader would not marvel at the works of Hayao Miyazaki without feeling some kind of strange proximity, a special and enchanted link with nature, or at the watching of Yuki Urushibara’s less known but outstanding Mushishi (蟲師)?
Several shared aspects of writing and language were as much attractive and seducing to us and have doubtlessly motivated that choice :
Tolkien's fondness for drawing and shape aesthetics are well known, and, fore sure, it would express itself throughout the shaping of his writing systems.
Some Asian languages still bear today such characteristics within their own systems, sublimated in the ancestral and perpetuated art of calligraphy. Moreover, the Japanese writing being based in its simplest form on syllabaries (the katakana and the hiragana), we've almost felt invited here to try the challenge of using the Elvish phonetic writing system to transcribe that specificity! An exercise that would show, otherwise, the adaptability and richness of the Tengwar system devised by Tokien.
三つの指輪は、空の下なるエルフの王に、
七つの指輪は、岩の館のドワーフの君に、
九つは、死すべき運命の人の子に、
一つは、暗き御座の冥王のため、
影横たわるモルドールの国に。
一つの指輪は、すべてを統べ、
一つの指輪は、すべてを見つけ、
一つの指輪は、すべてを捕らえて、
くらやみのなかにつなぎとめる。
影横たわるモルドールの国に。
The ring poem, translation by Teiji Seta
A note on the Hepburn romanization (rōmaji)
The Japanese language has several official romanizations (rōmaji) - norms describing how to write Japanese with the Latin alphabet. Each one of those has its qualities and flaws, and it was not that obvious to make a clever choice adapted to tengwa transcription. However, transcription problematics strongly invite to use as unambiguous a norm as possible, that is to say that the pronounciation should be deduced with the thinnest possible context. Norms that stick to phonetics, are thus, in the matter of tengwa transcription, the most suitable ones.
In that respect, the choice for the Hepburn romanization seemed the best one, as it would show the smallest amount of problems after experimenting. Moreover, it has the great advantage of being widely used both outside and inside Japan and is probably the most intuitive for the average Westerner (this was admittedly the norm that we were the most familiar with).
Nevertheless, although being based on pronounciation, it tends to oversimplify some distinctions between sounds or combinations of sounds that have weakened (more or less, depending on dialects or accents) or even where lost in the modern pronounciation of Japanese, but are still preserved within the kana writing. The mode that we propose thus requires to use our own disambiguation norm for rōmaji. These cases are the variants of the Japanese /D/ serie : ぢ / ヂ to be written dji instead of ji , づ / ヅ to be written dzu instead of zu, ぢゃ / ヂャ to be written dja instead of ja, ぢゅ / ヂュ to be written dju instead of ju et ぢょ / ヂョ to be written djo instead of jo. Their notation within the standard Hepburn norm clash with their counterpart variants of the /Z/ serie (see summary table below, corrections are noted in red).
Vowels
Japanese is characterized by a simple syllabic structure based on a consonant-vowel scheme, optionally followed by a single nasal consonant (called moraic nasal). Hence the most natural choice for a mode with tehtar, where those ones are carried by the consonant tengwa that precedes.
Moreover, our task is largely eased by the fact that Japanese has five vowels, which are almost identical to Quenya's. Only /u/ is slightly different in pronounciation (the Japanese /u/ is a compressed vowel, meaning that the margins of the lips are tense and drawn together in such a way that the inner surfaces are not exposed). It is natural thus to reuse the same tehtar as in the standard Quenya modes. Another common feature of Quenya and Japanese it the distinction between two vowel lengths, short and long (chôon). To note the vocalic lengthening, in a purpose of regularity and concision, our mode uses by default double tehtar (except for the a where we use the reversed version of the a tehta).
Hiragana. We regularize with a long vowel the classical combinations of Japanese : kana in /a/ + あ for /aː/, kana in /i/ + い for /iː/, kana in /u/ + う for /uː/, kana in /e/ + い for /eː/ et kana in /o/ + う for /oː/. It's worth noting that in addition of these cases, we systematically regularize with a long vowel the more irregular combinations ねえnee (e.g. お姉さん 『おねえさん』oneesan), ええee (e.g. ええ 『ええ』 ee), とおtoo (e.g. 通る 『とおる』tooru), おおoo (e.g. 狼 『おおかみ』ookami).
Katakana. By regularity, we extend these previous combinations to the katakana : even if not usual, they can be found there - those are the cases where the katakana transcribe words of Japanese or Chinese origin. Moreover, because in its most common usage the katakana uses the chōonpu (ー) to mark the vocalic lengthening, that one is of course handled by the mode, which accepts a similar usage in hiragana as well (though that's not orthodox).
Rōmaji. The mode accepts the common uses from the Hepburn romanization for long vowels : the macron, the circumflex accent (ex: ō, ô), but also acute and grave accents (by commodity) and the redoubling of vowels, combinations for which the mode models its treatment on the hiragana. Thus, redoubled vowels will be treated as long if they appear in standard Japanese combinations (ex: kaa, chii, fuu, tou, mei, nee, toobut neitherkee nor koo). It is advised to prefer the latest form, called wāpuro rōmaji (ワープロ・ローマ字), for long vowels, i.e. kaa instead of kâ, tou instead of tô, because it better preserves the Japanese phonology and is compliant with the option described just below. Conversely, as provided by the common usage, the apostrophe may be used to disambiguate a group that would be falsely treated as a long vowel, or even possibly disambiguate the n + vowel group. Note: the usage that consists in adding an extra h after a vowel to lengthen it is not accepted by the mode (because too ambiguous).
Chōon option. However, you can chose not to confound the long vowels so as to keep in the tengwar writing the same distinctions that those appearing in kana. An example of use of that option with the word 『とうめい』tōmei “transparent”: with confusiontinco/oo/malta/ee / without confusiontinco/o/telco/u/malta/e/telco/i. However, when the without confusion option is chosen, you can still make use of the chōonpu (ー) in an unorthodox way to locally force the confusion. Example of a mixed case with two long vowels, where the without confusion option is chosen, but where the confusion is forced on the second vowel : 『とうめー』tinco/o/telco/u/malta/ee. Moreover, when writing in Latin letters, we advise to use the wāpuro rōmaji because they will preserve the same distinctions as the kana.
It is not a common usage in Japanese writing to separate words with blanks ; thus the word separator | can be used to clarify the separation between two joined words that could potentially generate an ambiguous kana sequence that would look like a long vowel. It can also be employed, just like the apostrophe, to split the ei and ou sequences in exceptional cases where they would not represent long vowels, but a sequence of two distinct vowels in hiatus. It is by the way advised to systematically use the word separator between words so as to avoid any problem (or even blanks if you'd like to separate words).
A
I
U
E
O
telco/a
あアa
telco/i
いイi
telco/u
うウu
telco/e
えエe
telco/o
おオo
telco/arev
ああアーā
telco/ii
いいイーī
telco/uu
ううウーū
telco/ee
えいエーē
telco/oo
おうオーō
tinco/a
たタta
tinco/i
ちチchi
tinco/u
つツtsu
tinco/e
てテte
tinco/o
とトto
tinco/arev
たあターtaa
tinco/ii
ちいチーchii
tinco/uu
つうツーtsuu
tinco/ee
ていテーtei
tinco/oo
とうトーtou
Gojūon / Yōon
The basis : the Gojūon
For the transcription of the gojūon, our mode uses the following principles :
Conservation of the gojūon classes. One and only one tengwa is used for each class of the gojūon (ex. tinco pour ta / chi / tsu / te / to).
Distinction between voiceless and voiced consonants. In Japanese, the gojūon kana represent by default syllables with an initial voiceless consonant ; their counterpart kana with an initial voiced consonant derive from them by adding a “voicing dot” dakuten( ゙). In tengwar, this distinction will be marked by the difference between simple bow (or lúva in elvish) tengwar for voiceless consonants and double bow Tengwar for voiced consonants. That scheme is recurrent in Tolkien's modes, and since Japanese marks voicing just as systematically, the analogy was tempting. And it extends easily to the s / z (silme / esse) couple.
Conservation of the H/P/B relation. In Japanese, there exists a phonological relation between h, b and p. The reason is historical: Ancient Japanese /p/ evolved early towards modern /h/, then a new /p/ was reintroduced later for Chinese loanwords. In middle Chinese, those consonants are classified onto a “voicing” (litt. “turbidity”) hierarchy with three levels : clear (voiceless), half-clear (half-voiced, in reality aspirated), and turbid (voiced), which does not correspond to the Western phonetic classification of these sounds. Japanese syllabaries, accordingly to that Chinese loaning, thus make that classification appear through the dakuten( ゙) “voicing dot” (litt. “turbidity dot”) and the handakuten( ゚) “half-voicing dot”. (litt. “half-turbidity dot”) ; the Japanese writing system aligns, for the same reason, the /t/, /h/, /k/ phonemes (as well as /s/) on the same class of voiceless/clear consonants, the /d/, /b/, /g/ (as well as /z/) on the same class of voiced/turbid consonants and thus isolates the /p/ phoneme in a separate class “in-between”. That is reflected in our Tengwar table with the two first lines. Moreover, h,b and p belong to the same column for their labial relation.
Elvish Option. Although that logic follows a strict parallel with the Japanese writing system, it can however disconcert regular scholars of Tolkienian Tengwar modes and classical phonetics, since a large majority of modes designed for European or Elvish languages use the voiceless stops t, p et k as a reference. For that reason, we gave the ability, through an option, to invert the position of the p and the h, which should correspond undoubtedly to a more elvish reflex. And, charmingly, will take us closer to Ancient Japanese !
Non use of basic tengwar for foreign languages. With the default options, every foreign language will stand out from the Japanese system through a graphical “anomaly” (subscript diacritic, extended tengwar).
Non use of raised stems. We wanted to create an interesting graphical regularity effect by proscribing the use of raised stem tengwar. It has the advantage of reflecting the regularity of Japanese elocution, and letting the diacritics breathe. As we'll see below, some extended Tengwar (with double stems) will be used for foreign phonemes ; they will thus show up as "anomalies".
Elvish habits. Some options will allow, however, to override these two last rules and use some free Tengwar to stick to the more “typical” uses of classical Elvish modes.
Palatalized : Yōon
calma/i<
KY
calma/i</a
calma/i</u
calma/i</o
きゃ
きゅ
きょ
キャ
キュ
キョ
kya
kyu
kyo
yanta, telco/i</
Y
yanta/a
yanta/u
yanta/o
や
ゆ
よ
ヤ
ユ
ヨ
ya
yu
yo
In addition of the gojūon, Japanese has a serie of syllables with palatalized consonants, whose writing derive from the gojūon in a systematical way, namely the yōon. Its kana derive from their associated gojūon kana ending in -i followed by a small ya (ャ), yu (ゅ) or yo (ょ). To render that feature in tengwar, we simply use the subscribed dot unutixë as a palatalization sign. The advantages of that graphical choice are the following :
It is compatible with the "voicing" system of the gojūon described above.
It allows to deduce the entire yōon table with a unique rule.
It is compatible with the vocal lengthening, prenazalisation and gemination.
It can be easily extended to -ye for the foreign kana.
For the independent gojūon syllables ya, yu, yo two logics are in competition. The first one is to use the short carrier telco with unutixë, in a logical and regular way. However, for readability reasons, we prefer using yanta, which is partly an Elvish reflex (but also reflects the Japanese logic of having them as separate gojūon entities). Option. The use of telco is given as an option.
Elvish option. One could also wish to use the double unutixë for palatalization, like the classical Quenya mode. That option is also proposed, even if the unutixë is preferred for readability reasons.
Moraic nasal
noldo/calma, calma/nasal
NK
ん + K Hiragana
ン + K Katakana
In Japanese, all syllables can potentially be followed by a single nasal of variable articulation, which is noted by the hiragana ん or katakana ン and that we will transcribe with the noldo tengwa. Elvish option. Since the moraic nasal prenazalises the following consonant by assimilating its articulation point, we propose an alternative version to represent it, by using the nazalisation bar on the following Tengwa (if there is one).
Geminates
halla/calma, calma/geminate, calma/calma
KK
っ + K Hiragana
ッ + K Katakana
Consonant gemination is transcribed by adding a preceding gasdil (or halla), a simple vertical stroke that fills the same role as the sokuonっ in Japanese. Elvish options. We propose, as alternative solutions, the subscript gemination bar, or even, the redoubling of the Tengwa.
The wa / wo / e particles
hwestasindarinwa
WA (topic)
は* wa* ha*
vaia
WO (object)
を ヲ wo o*
12
E (direction)
へ* he* e*
Japanese grammatical particles are numerous, and some of them are ambiguous for tengwa transcription because their pronunciation diverges from the way they are written in kana ; we will then use the asterisk to disambiguate these cases. The choice for the assigned tengwar comes from the fact that we use úre for the transcription of the japanese /w/ phoneme. The two particles は (kana for ha but pronounced wa as a thematic particle) and を (nowadays pronounced o, anciently wo) are nicely eligible to be transcribed by the two graphical variants of úre, hwesta sindarinwa and vaia - all the more that Quenya uses úre for u when it is the second element of a diphthong, where it is closed to a [w]. By extension, the へ particle (kana for he, nowadays pronounced e, and anciently we, as a directional particle) is assigned the tengwa for the elvish digit 12, for purely graphical reasons (it also looks like a variant of úre).
I
II
III
IV
1
tinco
T
tinco/a
tinco/i
tinco/u
tinco/e
tinco/o
た
ち
つ
て
と
タ
チ
ツ
テ
ト
ta
chi
tsu
te
to
parma
H (P)
parma/a
parma/i
parma/u
parma/e
parma/o
は
ひ
ふ
へ
ホ
ハ
ヒ
フ
ヘ
ほ
ha
hi
fu
he
ho
calma
K
calma/a
calma/i
calma/u
calma/e
calma/o
か
き
く
け
こ
カ
キ
ク
ケ
コ
ka
ki
ku
ke
ko
quesse
KW
quesse/a
quesse/i
quesse/e
quesse/o
-
-
-
-
クァ
クィ
クェ
クォ
kwa
kwi
kwe
kwo
2
ando
D
ando/a
ando/i
ando/u
ando/e
ando/o
だ
ぢ
づ
で
ど
ダ
ヂ
ヅ
デ
ド
da
dji
dzu
de
do
umbar
B
umbar/a
umbar/i
umbar/u
umbar/e
umbar/o
ば
び
ぶ
べ
ぼ
バ
ビ
ブ
ベ
ボ
ba
bi
bu
be
bo
anga
G
anga/a
anga/i
anga/u
anga/e
anga/o
が
ぎ
ぐ
ゲ
ご
ガ
ギ
グ
げ
ゴ
ga
gi
gu
ge
go
ungwe
GW
ungwe/a
ungwe/i
ungwe/e
ungwe/o
-
-
-
-
グァ
グィ
グェ
グォ
gwa
gwi
gwe
gwo
3
sule
-
formen
F
formen/a
formen/i
formen/e
formen/o
-
-
-
-
ファ
フィ
フェ
フォ
fa
fi
fe
fo
aha
-
hwesta
-
4
anto
-
ampa
V
ampa/a
ampa/i
ampa/u
ampa/e
ampa/o
-
-
-
-
-
ヴァ
ヴィ
ウゥ
ヴェ
ヴォ
va
vi
vu
ve
vo
anca
-
unque
-
5
ore
-
vala
P (H)
vala/a
vala/i
vala/u
vala/e
vala/o
ぱ
ぴ
ぷ
ぺ
ぽ
パ
ピ
プ
ペ
ポ
pa
pi
pu
pe
po
anna
-
vilya
-
6
numen
N
numen/a
numen/i
numen/u
numen/e
numen/o
な
に
ぬ
ね
の
ナ
ニ
ヌ
ネ
ノ
na
ni
nu
ne
no
malta
M
malta/a
malta/i
malta/u
malta/e
malta/o
ま
み
む
め
も
マ
ミ
ム
メ
モ
ma
mi
mu
me
mo
noldo
N'
noldo
ん
ン
n/n'
nwalme
-
7
romen
R
romen/a
romen/i
romen/u
romen/e
romen/o
ら
り
る
れ
ろ
ラ
リ
ル
レ
ロ
ra
ri
ru
re
ro
arda
-
lambe
L
lambe/a
lambe/i
lambe/u
lambe/e
lambe/o
-
-
-
-
-
ラ゜
リ゜
ル゜
レ゜
ロ゜
la
li
lu
le
lo
alda
-
8
silme
-
silmen
S
silmen/a
silmen/i
silmen/u
silmen/e
silmen/o
さ
し
す
せ
そ
サ
シ
ス
セ
ソ
sa
shi
su
se
so
esse
-
essen
Z
essen/a
essen/i
essen/u
essen/e
essen/o
ざ
じ
ず
ぜ
ぞ
ザ
ジ
ズ
ゼ
ゾ
za
ji
zu
ze
zo
9
hyarmen
-
halla
-
yanta
Y
yanta/a
yanta/u
yanta/o
や
ゆ
よ
ヤ
ユ
ヨ
ya
yu
yo
ure
W
ure/a
ure/i
ure/e
わ
ゐ
ゑ
ワ
ヰ
ヱ
wa
wi
we
Hepburn romanization disambiguation.
Japanese characters that have become obsolete.
Tengwar that are not used by default, but only as an option.
Foreign phonems, not present in the Japanese phonology.
Gojûon / Yôon summary
We summarize the principles evoked above in the table below.
Gojūon
telco/a あ ア a
telco/i い イ i
telco/u う ウ u
telco/e え エ e
telco/o お オ o
calma/a か カ ka
calma/i き キ ki
calma/u く ク ku
calma/e け ケ ke
calma/o こ コ ko
silmen/a さ サ sa
silmen/i し シ shi
silmen/u す ス su
silmen/e せ セ se
silmen/o そ ソ so
tinco/a た タ ta
tinco/i ち チ chi
tinco/u つ ツ tsu
tinco/e て テ te
tinco/o と ト to
numen/a な ナ na
numen/i に ニ ni
numen/u ぬ ヌ nu
numen/e ね ネ ne
numen/o の ノ no
parma/a は ハ ha
parma/i ひ ヒ hi
parma/u ふ フ fu
parma/e へ ヘ he
parma/o ほ ホ ho
malta/a ま マ ma
malta/i み ミ mi
malta/u む ム mu
malta/e め メ me
malta/o も モ mo
yanta/a や ヤ ya
yanta/u ゆ ユ yu
yanta/o よ ヨ yo
romen/a ら ラ ra
romen/i り リ ri
romen/u る ル ru
romen/e れ レ re
romen/o ろ ロ ro
ure/a わ ワ wa
ure/iゐ ヰ wi †
ure/eゑ ヱ we †
vaiaを ヲ wo
noldo ん ン n /n'
anga/a が ガ ga
anga/i ぎ ギ gi
anga/u ぐ グ gu
anga/e げ ゲ ge
anga/o ご ゴ go
essen/a ざ ザ za
essen/i じ ジ ji
essen/u ず ズ zu
essen/e ぜ ゼ ze
essen/o ぞ ゾ zo
ando/a だ ダ da
ando/i ぢ ヂ dji
ando/u づ ヅ dzu
ando/e で デ de
ando/o ど ド do
umbar/a ば バ ba
umbar/i び ビ bi
umbar/u ぶ ブ bu
umbar/e べ ベ be
umbar/o ぼ ボ bo
vala/a ぱ パ pa
vala/i ぴ ピ pi
vala/u ぷ プ pu
vala/e ぺ ペ pe
vala/o ぽ ポ po
Yōon
calma/i</a きゃ キャ kya
calma/i</u きゅ キュ kyu
calma/i</o きょ キョ kyo
silmen/i</a しゃ シャ sha
silmen/i</u しゅ シュ shu
silmen/i</o しょ ショ sho
tinco/i</a ちゃ チャ cha
tinco/i</u ちゅ チュ chu
tinco/i</o ちょ チョ cho
numen/i</a にゃ ニャ nya
numen/i</u にゅ ニュ nyu
numen/i</o にょ ニョ nyo
parma/i</a ひゃ ヒャ hya
parma/i</u ひゅ ヒュ hyu
parma/i</o ひょ ヒョ hyo
malta/i</a みゃ ミャ mya
malta/i</u みゅ ミュ myu
malta/i</o みょ ミョ myo
romen/i</a りゃ リャ rya
romen/i</u りゅ リュ ryu
romen/i</o りょ リョ ryo
anga/i</a ぎゃ ギャ gya
anga/i</u ぎゅ ギュ gyu
anga/i</o ぎょ ギョ gyo
essen/i</a じゃ ジャ ja
essen/i</u じゅ ジュ ju
essen/i</o じょ ジョ jo
ando/i</a ぢゃ ヂャ dja
ando/i</u ぢゅ ヂュ dju
ando/i</o ぢょ ヂョ djo
umbar/i</a びゃ ビャ bya
umbar/i</u びゅ ビュ byu
umbar/i</o びょ ビョ byo
vala/i</a ぴゃ ピャ pya
vala/i</u ぴゅ ピュ pyu
vala/i</o ぴょ ピョ pyo
Extended Katakana for foreign words
Principles
A summary table of extended Katakana is available here on Wikipédia. Our main rule is that, if possible, the tengwar chosen for their transcription are derived from basic tengwar from the gojūon by applying modifications to them. In some cases, we will specifically use additional tengwar.
parma/unutixe
Palatalization : some extended Katakana represent non-Japanese palatalized versions of sounds which are present in the gojūon. This can particularly be observed for all -ye sounds, which are absent from the Japanese phonology but for which we can seamlessly extend the system devised for the yōon (although modern Japanese does not have any kana for ye, large or small). This notation for palatalization may also be mechanically applied to the additional tengwar that can accept palatalized versions.
parma/u<
Labialization : some extended Katakana represent non-Japanese labialized versions of sounds which are present in the gojūon. Namely, these are all the kw- and gw- variants coming from k- and g- (These sounds had formerly existed in Japanese but they merged into k and g in the modern language). In that case, we use a generalization of the system set up for the yōon : instead of unutixë (subscript dot), we subscribe the u tehta to the carrier tengwa so as to mark the labialization of the consonant.
parma/sarince
Assibilation : some extended Katakana represent non-Japanese assibilated versions of sounds which are present in the gojūon. Namely, these are all the ts- variants derived from t-. In Japanese, the assibilation of t- occurs automatically before the /u/ vowel and does not need to be specified in tengwar. In the other cases, we use a sa-rince to mark assibilation. It is worth noting the the variant ツュtsyu displays both marks of assibilation and palatalization.
parma/thinnas
Annulation : among the basic syllables of the gojūon, some consonants may include automatic articulatory modifications depending on the following vowel. In the /t/ serie for example, we find ちchi, whose consonant is naturally palatalized, and ツtsu which consonant is naturally assibilated. Those modifications are characteristic of the natural Japanese phonetic system and do not need to be specified. However, the use of the annulation tehta thinnas allows to bring back the consonant to its basic, phonetically unmodified version. Regarding our two precedent examples, it allows us to derive ti and tu.
parma/lsd
Annulation + Palatalization : some extended Katakana represent foreign sounds that feature both the annulation of the automatic consonant modification of basic a syllable of the gojūon and a further re-palatalization.This is the case of テュtyu and デュdyu - coming from ツtsu and ヅdzu. Since the annulation thinnas and the palatalization unutixë are hard to combine, we chose the subscript circle to represent that special palatalization.
Additional tengwar
A few tengwar have been added to complete the system, when there is a need to represent syllables whose consonants do not exist in the phonetic Japanese system.
The voiced labiodental fricative v does not exist in Japanese. We will use the extended tengwa xampa : it is voiced, hence the double bow, and because of its labial feature, we put it in the b, h and p column to respect the phonetical logic of Japanese. Elvish option. The use of ampaampa is also possible.
The Voiceless labiodental fricative f does not exist in Japanese. However, another sound is quite close : h before the u voyelle has a voiceless fricative bilabial pronounciation (kana ふ transcribed fu in Hepburn). The extended katakana proposes to represent the labio-dental f of foreign words ; for that purpose, we will use in a logical way the extended tengwa xformen : as a voiceless consonant, it has only one bow, and as a labial we put it in the b, h and p column to respect the phonetical logic of Japanese. Elvish option. The use of formenformenis also possible.
Japanese does not make the distinction between the r and l liquids : it has a unique liquid, apical and slightly flapped (transcribed r in Hepburn). The extended katakana proposes, for foreign words, to represent a non-flapped lateral l-type variant, that we will note in an Elvish-logical way by lambëlambe.
yanta/i / telco/unutixe/i イィ yi
yanta/e / telco/unutixe/e イェ ye
ure/a ウァ wa
ure/i ウィ wi
ure/u ウゥ wu
ure/e ウェ we
ure/o ウォ wo
ure/unutixe/u ウュ wyu
xumbar/a ヴァ va
xumbar/i ヴィ vi
xumbar/u ウゥ vu
xumbar/e ヴェ ve
xumbar/o ヴォ vo
xumbar/unutixe/a ヴャ vya
xumbar/unutixe/u ヴュ vyu
xumbar/unutixe/e ヴィェ vye
xumbar/unutixe/o ヴョ vyo
calma/unutixe/e キェ kye
anga/unutixe/e ギェ gye
calma/u</a クァ kwa
calma/u</i クィ kwi
calma/u</e クェ kwe
calma/u</o クォ kwo
calma/u</a クヮ kwa
anga/u</a グァ gwa
anga/u</i グィ gwi
anga/u</e グェ gwe
anga/u</o グォ gwo
anga/u</a グヮ gwa
silmen/unutixe/e シェ she
essen/unutixe/e ジェ je
silmen/thinnas/i スィ si
essen/thinnas/e ズィ zi
tinco/unutixe/e チェ che
tinco/a/sarince ツァ tsa
tinco/i/sarince ツィ tsi
tinco/e/sarince ツェ tse
tinco/o/sarince ツォ tso
tinco/unutixe/u/sarince ツュ tsyu
tinco/thinnas/i ティ ti
tinco/thinnas/u トゥ tu
tinco/lsd/u テュ tyu
ando/thinnas/i ディ di
ando/thinnas/u ドゥ du
ando/lsd/u デュ dyu
numen/unutixe/u ニェ nye
vala/unutixe/u ヒェ hye
umbar/unutixe/u ビェ bye
parma/unutixe/u ピェ pye
xparma/a ファ fa
xparma/i フィ fi
xparma/e フェ fe
xparma/o フォ fo
xparma/unutixe/a フャ fya
xparma/unutixe/i フュ fyu
xparma/unutixe/e フィェ fye
xparma/unutixe/o フョ fyo
vala/thinnas/u ホゥ hu
malta/unutixe/e ミェ mye
romen/unutixe/e リェ rye
lambe/a ラ゜ la
lambe/i リ゜ li
lambe/u ル゜ lu
lambe/e レ゜ le
lambe/o ロ゜ lo
xumbar/a ヷ va
xumbar/i ヸ vi
xumbar/e ヹ ve
xumbar/o ヺ vo
Numerals
The mode accepts the modern numbering system, that uses arabic digits. In that case, the transcription is purely literal and goes from left to right. It also accepts the traditional Japanese numeral system, where we will transcribe the kanjis for the powers of 10 by the digit tengwar corresponding to the powers, with an additional suscript circle. In traditional numbering, we will not go beyond 108. But can you really count up to this :-) ?
1
1
一
2
2
二
3
3
三
4
4
四
5
5
五
6
6
六
7
7
七
8
8
八
9
9
九
0
0
〇 / 零
1/lsd
10
十
2/lsd
100
百
3/lsd
1 000
千
4/lsd
104
万
8/lsd
108
億
Punctuation
Seamlessly, Japanese punctuation signs will be transcribed into tengwar just like their European or Elvish counterparts.
Raw tengwar usage
Like all other tengwar modes, this mode handles the “raw tengwar” feature, which allows the straightforward spelling of a tengwar series to be kept unmodified in transcription – which can be useful to incorporate some tengwar text that does not fit into the mode’s context. For more information, unfold the manual with the romen/ara/o button on the top right of the interface.
Cirth-Modus für Khuzdul nach der Bestimmung fürs Angerthas Moria, von Tolkien im Anhang E des Herrn der Ringe vorgelegt und der Inschrift auf Balins Grab in dem Herrn der Ringe, Buch II, Kapitel 2 veranschaulicht.
Dieser Modus ist ein Beitrag von Da Def aus der Expanse Science-Fiction Fernsehserie Fan-Community. Es ermöglicht das Lang Belta der Bewohner des Asteroidengürtels in Tengwar zu transkribieren. Lang Belta ist eine original Kunstsprache, erfunden von Nick Farmer für die TV-Serie. Wir freuen uns, ein solches Experiment begrüßen zu dürfen, das Tolkiens Einfluss auf moderne Imaginäre perfekt veranschaulicht.
Wir haben die Gebrauchsanweisung noch nicht auf Deutsch übersetzt, so legen wir hier vorläufig die englische Fassung vor.
A word of introduction
The following tengwar mode has been designed by from the Expanse fan community (channel #showxa-wit-milowda on discord), and is his contribution to Glaemscribe. It intends to allow the transcription of lang belta creole from the Expanse TV series (a conlang designed by Nick Farmer) into tengwar.
We are delighted to host this experiment, because as far as it may seem at first from the paths of Middle Earth, it highlights how the linguistic, so special form of art of Tolkien has illuminated the realms of speculative fiction (and more). In his will to recreate a mythology for his country, Tolkien may have participated to set mechanisms that are now part of our world's modern "mythology", built from Fantasy, Science-Fiction, Fantastic and other imaginariums, and where conlangs may play a fundamental and powerful introspection role - at the crossing of imagination, philosophy, psychology. But enough glaemscrafic talk : we now give the floor to Dave who will present his work in the next paragraphs.
Overview
Why write lang belta in tengwar? Belters and Quendi have much in common : they like stars, they hate shorties, and they live far from the homes of mankind. And, more seriously, we do have the approbation of the language creator himself :
Belter doesn't have a standard orthography. It's reasonable to assume that in different parts of the Belt, it is written in the script most familiar to those speakers.
— Nick Farmer (@Nfarmerlinguist), May 26, 2018, on Twitter
Note that this mode is meant to express the show language, not for the original book language.
Like all non-auxlangs, LB has significant variation. To keep things simple, all descriptions below are for the general cases, and do not take into account minor exceptions.
The TV series logo, copyright of its publishers
Phonology
The main vowels are:
/i/
/e/
/a/
/ow/
/o/
/u/
/a/ is [æ] but is more common than /ow/ [ɒ] so in accordance with the latin orthography and to make implict-a a useful feature, the òmatehtar have been assigned as described.
As an approximation, the series [i] [e] [æ] [ɒ] [o] [u] is approximately: peat, pate, pat, bought, boat, boot.
/ã/ is currently a hapax, in shãsa.
All the consonants are:
/t/
/p/
/ch/
/k/
/d/
/b/
/dzh/
/g/
-
/f/
/sh/
/x/
-
/v/
-
-
/n/
/m/
/ny/
/ng/
-
/w/
/y/
-
/r/
-
/l/
-
-
/s/
-
/z/
Phonotactics
The basic syllable is either an open CV or a closed CVC. An initial V is also observed.
Because we also infer strong constraints on inter-syllabic consonant clusters and final consonants, it is easier to analyze simple words as (V){C_iV}(C_f), where:
C_i is any single consonant or a limited number of clusters: t+n, l+t, nasal+C
C_f are a limited number of final single consonants.
The following lang belta phrase contains all the extant vowels and consonants, in typical patterns:
Sources on Monday said: while police are being selfish, dealers' navigational chances are fragile.
— Attempt of a literal translation (breaking news!)
An article by Eric Armstrong, the speech coach for The Expanse show, claims that /n/ == /ny/ == /ng/ are allophones (the VASTA Voice, volume 10, issue 4 September 2015). However, Nick Farmer's orthography, while it generally agrees:
only /n/ occurs in initial position
most medial occurrences are /ny/
only /ng/ occurs in final position
does not completely support it. There are some medial occurrences of /ng/, as well as the medial /n/ of kena, which must obviously be carefully pronounced to avoid any confusion with keya. It does remain possible that there is only one phoneme /n/ and the [n] [ɲ] [ŋ] phones are traditionally pronounced (driven by etymological considerations?) as Farmer has notated them. However, written material on the show reveals that the latin orthography does distinguish the three consonants, e.g. writing showxating instead of *showxatin.
Orthography
Vowels
Vowels are represented with ómatehtar on the tengwa of their syllable.
The nasalization mark has been tentatively used for the single occurrence of shãsa, in case other nasalized vowels are introduced.
i
e
a
ow
o
u
telco/i
telco/e
telco/a
telco/arev
telco/o
telco/u
Consonants
Consonants are represented with their tengwar exactly in the Mannish fashion, such as the Westron mode.
In the example above, we used the common prose mode (nawit naterash), where consonants are always written.
Wit yaterash
There are also options for a poetic mode (wit yaterash), which attempt to make each grapheme roughly equivalent to each syllable. In order to do this, two things must be done.
First, the previous closed syllable's closing consonant is marked underneath the current consonant, as follows:
t : thinnas (a bar means a stop)
l : palatal (dots indicate the lateral airflow around the tongue for /l/)
m,n : lsd circle
This way the characters read left to right, bottom to top. An example :
Kepelesh imbobo belta, beratna?
⸱
— in prose mode (nawit naterash)
⸱
— in poetic mode (wit yaterash)
⸱
— in poetic mode (wit yaterash, bikang)
Where apartment belter, brother?
— word for word translation
Where are the belter quarters, bro?
— literal translation
But what just happened to the -lesh of kepelesh?
In order to preserve the common reading pattern, the most sophisticated form of yaterash script completely elides final consonants, only indicating their presence by a geminate sign.
I
II
III
IV
1
tinco
t
parma
p
calma
ch
quesse
k
2
ando
d
umbar
b
anga
dzh
ungwe
g
3
....
formen
f
aha
sh
hwesta
x
4
....
ampa
v
....
....
5
numen
n
malta
m
noldo
ny
nwalme
ng
6
....
vala
w
anna
y
....
7
romen
r
....
lambe
l
....
8
....
silmen
s
....
essen
z
9
....
....
....
....
For the convenience of readers who may not be familiar with the texts, there is also the beacon bikang sub mode, as in the example above, in which hints to the elided final consonants are provided via ómatehtar underneath the tengwa. These hints divide the possible final consonants into classes which have been chosen to minimize potential confusion, but unfortunately they disturb the natural scanning left-to-right and bottom-to-top scan pattern.
We also provide options for representing nasal consonants using extended tengwar (lowng option) or the classical elvish consonant modifier (kuwendi option).
m,t
ng
f,k,p
l,x,sh
telco/o<
telco/ee<
telco/u<
telco/e<
Nota Bene
Lang belta is used by humans, not elves, so, while an option is given to chose the numbering system :
Base 10, big endian is the numeric default
In principle, silme and esse are always inverted (nuquerna), even without vowels (phonotactic constraints would prevent this in well-formed belter words, anyway)
Because of absence of [θ] and [ð], it would in principle have been possible to move /s/ and /z/ to their natural phonetic places as dental fricatives (and then move /l/ and /r/ to the unused slots next to /w/ and /y/) but we have chosen here to stick with the traditional graphemes for mannish languages such as Westron.
Anyone who wishes to experiment with a more austere version using only the first 24 tengwar is free to use the raw mode escape to do so.
The #learning-lang-belta and #showxa-wit-milowda channels on the Expanse Discord are a nice community, some of whom even have a smattering of Quenya.
Acknowledgements
This work would not have been possible without the encouragement and support of da Talagang (Benjamin Babut) as well as the fine xunyamwala (scholars) mentioned above.
Purposes and thoughts
Who might the lang belta mode be used by?
Fen who left the mundanes on earth, seeking a new life in the belt in vast colony ships called Sepingedizi ("spindizzies")?
Why write lang belta in tengwar?
Not only as a small token of resistance against inner-planet alphabetic-cultural hegemony, but also simply because it allows belters to express beautiful sentiments in beautiful script :
Gufovedi
demang|tenye
malimang|so
gufovedi
Gufovedi, demang tenye malimang so gufovedi.
— vanimar, vanimálion nostari
... and because fandom is more fun when crossing the streams.
Wa setara
ando|du|lush
detim|pelesh
mi|pelesh|to
Wa setara ando du lush detim pelesh mi pelesh to.
— Elen síla lúmenn' omentielvo
Modus für die Umschrift des Altenglischen aus dem lateinischen Alphabet in angelsächsische Runen oder Futhorc, die in England vom 5. bis zum 11. Jahrhundert gebraucht wurden, und die Tolkien im Vorwort des Hobbits veranschaulichte. Der volle Gebrauch dieser Umschrift verlangt, dass man die palatale oder velare Bedeutung der Konsonanten c, g und der Häufung sc klarstellt: zu diesem Zweck soll man die Palatalen mit Überpunkt zeichen (ċ, ġ, sċ).
Tengwar-Modus für Altenglisch, von dem sogennanten „Text II“ Manuskript in The Notion Club Papers veranschaulicht, und von Christopher Tolkien in Sauron defeated S. 318-327 beschrieben. Er berücksichtigt mehr Lautunterschiede als die historichen Schreibungen des Altenglisches mit dem lateinischen Alphabet, und beruht daher auf einer ad hoc Lautierung, die die Bedeutung von besonderen Buchstaben klarstellt: c (wird c oder ċ), g (g, ġ, ȝ oder j), h (h, χ oder ç), i (i oder ĭ), f (f oder v), s (s oder z) und sc (sc oder sċ). Lange Vokale werden mit einem Akut gezeigt. Die Silbentrennung kann man mit einem senkrechten Strich klarstellen.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Tengwar-Modus für Altenglisch, von dem sogennanten „Text I“ Manuskript in The Notion Club Papers veranschaulicht, und von Christopher Tolkien in Sauron defeated S. 318-327 beschrieben. Er berücksichtigt mehr Lautunterschiede als die historichen Schreibungen des Altenglisches mit dem lateinischen Alphabet, und beruht daher auf einer ad hoc Lautierung, die die Bedeutung von besonderen Buchstaben klarstellt: c (wird c oder ċ), g (g, ġ, ȝ oder j), h (h, χ oder ç), i (i oder ĭ), f (f oder v), s (s oder z) und sc (sc oder sċ). Lange Vokale werden mit einem Akut gezeigt. Die Silbentrennung kann man mit einem senkrechten Strich klarstellen.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Modus für die Umschrift des Altnordischen aus seiner normalisierten Rechtschreibung mit dem lateinischen Alphabet in nordische Runen oder Futhark, in eine späte, durch das lateinische Alphabet beeinflusste Form, die im Codex Runicus veranschaulicht ist und in Skandinavien ab dem 13. Jahrhundert gebraucht wurde.
Modus für die Umschrift des Altnordischen in nordische Runen oder jüngere Futhark, die in Skandinavien vom 9. bis zum 12. Jahrhundert gebraucht wurden. Die Umschrift beruht auf der normalisierten Rechtschreibung des klassischen Altnordischen im lateinischen Alphabet, verlangt aber zwei zusätzliche Lautunterscheidungen der älteren Sprache der Runennischriften: den klassischen altnordischen Vokal /a/ soll man entweder a oder ą schreiben, je nachdem, ob er früher oral oder nasal war, und den klassischen altnordischen Konsonant /r/ soll man entweder r oder ř schreiben, je nachdem, ob er aus einem urgermanischen /r/ oder /z/ entstand.
Sarati-Modus für Quenya, nach Tolkiens gewöhnlicher Bestimmung für diese Sprache. Eine ausführliche Analyse auf Englisch von Måns Björkman Berg liegt auf Amanyë Tenceli vor. Auf Deutsch gibt es eine Zusammenfassung der Bestimmung auf Ardapedia.
„Klassischer“ Tengwar-Modus für Quenya, von Tolkien im Anhang E des Herrn der Ringe beschrieben und vom Namárië-Manuskript in The Road Goes Ever On S. 65 veranschaulicht. Eine ausführliche Analyse auf Englisch von Måns Björkman Berg liegt auf Amanyë Tenceli vor. Eine kürzere auf Deutsch hat Gernot Katzer geschrieben.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Cirth-Modus für Sindarin/Noldorin nach der Bestimmung fürs Angerthas Daeron, von Tolkien im Anhang E des Herrn der Ringe vorgelegt.
Mittelpunkt und Bindestrich
Der Mittelpunkt · dient als Wörteverbindung, besonders zwischen einem grammatischen Wort, das eine Mutation bewirkt, und dem folgenden Wort, dessen Anfang diese Mutation bezeigt. Man kann ihn auch benutzen, um den Digraph ng eindeutig zu machen: weiter unten. Komponenten mit Mittelpunkt oder Bindestrich als Wörterverbindung werden als ein einziges Wort transkribiert. In Betracht der Verwendbarkeit kann man das Sternchen * genauso benutzen.
Als Wörteverbindung gebrauchte Tolkien auch den Bindestricht, aber er gab ihn zugleich einen anderen Zweck als Trenner der Bestandteile einer Zusammensetzung, mit Einfluss auf der Tengwarschreibung. Zum Beispiel schreibt er in seiner Transkription von A Elbereth Gilthoniel in Beleriand-Modus das Doppelwort palan-dírielparma/osse/lambe/osse/ore/ando/telco/e/romen/telco/yanta/lambe statt parma/osse/lambe/osse/ando/nasal/telco/e/romen/telco/yanta/lambe: die Trennung der zwei Komponenten wird durch zwei einzelne Tengwar bezeigt, obwohl ein Konsonant mit vorstehendem Nasal am selben Artikulationsort in Wortmitte am häufigsten durch einen Tengwa mit überstehendem Tilde transkribiert wird.
Wir haben beschlossen, den Bindestricht defaultmäßig für eine Trennung zu halten (ganz wie ein Leerzeichen). So kann man die zwei Funktionen durch verschiedene von Tolkien gebrauchte Zeichen unterscheiden: der Mittelpunkt · dient als Verbindung und der Bindestricht - als Trennung. Mann muss aber zugeben, dass diese Unterscheidung ihm fremd ist: in seinen Texten hat jedes der Zeichen in gleicher Weise manchmal die eine, manchmal die andere Funktion.
Eine Option erlaubt aber, den Bindestrich wie den Mittelpunkt als Verbindung zu benutzen. Auf diesem Fall kann man dennoch wenn Nnötig eine Trennung aufzwingen, und zwar mit dem senkrechten Strich |, der in jedem Glǽmscribe-Modus eine Worttrennung bedeutet.
Transkription von ng
Der Digraph ng wird in Tolkiens Umscrift von Sindarin zweierlei gebraucht: in Wortmitte bedeutet er die Konsonantenverbindung /ŋg/, am Wortende bedeutet er den einfachen Nasalkonsonant /ŋ/. Am Wortanfang sind vermutlich beide möglich, doch immer als Mutation eines /g/ nach verschiedenen Artikeln oder Präpositionen: /ŋ/ erscheint als Mutation eines alten einfachen /g/ (z. B. i·ngelaidh /i'ŋɛlaið/ „die Bäume“ (Singular galadh) während /ŋg/ erscheint als Mutation eines /g/, das aus einer älteren Konsonantenverbindung /g/ stammt (z. B. in·Gelydh /iŋ'gɛlyð/ „die Ñoldor“ (Singular Golodh). Die Stelle vom Mittelpunkt (oder Leerzeichen) macht die Transkription eindeutig, doch ist Tolkiens Gebrauch in der Tat sehr gemischt.
Wir haben also entschieden, ng als /ŋ/ noldo am Wortanfang und Wortende und als /ŋg/ anga/nasal im Wortmitte zu transkribieren. Am Wortanfang erlaubt der Mittelpunkt oder Bindestricht, die passende Mutation anzugeben: die Verbindung ·ng bedeutet /ŋ/ und die Verbindung n·g bedeutet /ŋg/. Die zusätzlichen Verbindungen ngg, ŋg, ñg entsprechen auch /ŋg/ und werden alle anga/nasal transkribiert.
„Beleriand“ Tengwar-Modus für Sindarin/Noldorin, mit vollständigen Tengwar für Vokale, von der Inschrift des Moria-Tores im Buch II, Kapitel 4 des Herrn der Ringe und dem A Elbereth Gilthoniel-Manuskript in The Road Goes Ever On S. 70 veranschaulicht. Eine ausführliche Analyse auf Englisch von Måns Björkman Berg liegt auf Amanyë Tenceli vor. Eine kürzere auf Deutsch hat Gernot Katzer geschrieben.
Mittelpunkt und Bindestrich
Der Mittelpunkt · dient als Wörteverbindung, besonders zwischen einem grammatischen Wort, das eine Mutation bewirkt, und dem folgenden Wort, dessen Anfang diese Mutation bezeigt. Man kann ihn auch benutzen, um den Digraph ng eindeutig zu machen: weiter unten. Komponenten mit Mittelpunkt oder Bindestrich als Wörterverbindung werden als ein einziges Wort transkribiert. In Betracht der Verwendbarkeit kann man das Sternchen * genauso benutzen.
Als Wörteverbindung gebrauchte Tolkien auch den Bindestricht, aber er gab ihn zugleich einen anderen Zweck als Trenner der Bestandteile einer Zusammensetzung, mit Einfluss auf der Tengwarschreibung. Zum Beispiel schreibt er in seiner Transkription von A Elbereth Gilthoniel in Beleriand-Modus das Doppelwort palan-dírielparma/osse/lambe/osse/ore/ando/telco/e/romen/telco/yanta/lambe statt parma/osse/lambe/osse/ando/nasal/telco/e/romen/telco/yanta/lambe: die Trennung der zwei Komponenten wird durch zwei einzelne Tengwar bezeigt, obwohl ein Konsonant mit vorstehendem Nasal am selben Artikulationsort in Wortmitte am häufigsten durch einen Tengwa mit überstehendem Tilde transkribiert wird.
Wir haben beschlossen, den Bindestricht defaultmäßig für eine Trennung zu halten (ganz wie ein Leerzeichen). So kann man die zwei Funktionen durch verschiedene von Tolkien gebrauchte Zeichen unterscheiden: der Mittelpunkt · dient als Verbindung und der Bindestricht - als Trennung. Mann muss aber zugeben, dass diese Unterscheidung ihm fremd ist: in seinen Texten hat jedes der Zeichen in gleicher Weise manchmal die eine, manchmal die andere Funktion.
Eine Option erlaubt aber, den Bindestrich wie den Mittelpunkt als Verbindung zu benutzen. Auf diesem Fall kann man dennoch wenn Nnötig eine Trennung aufzwingen, und zwar mit dem senkrechten Strich |, der in jedem Glǽmscribe-Modus eine Worttrennung bedeutet.
Transkription von ng
Der Digraph ng wird in Tolkiens Umscrift von Sindarin zweierlei gebraucht: in Wortmitte bedeutet er die Konsonantenverbindung /ŋg/, am Wortende bedeutet er den einfachen Nasalkonsonant /ŋ/. Am Wortanfang sind vermutlich beide möglich, doch immer als Mutation eines /g/ nach verschiedenen Artikeln oder Präpositionen: /ŋ/ erscheint als Mutation eines alten einfachen /g/ (z. B. i·ngelaidh /i'ŋɛlaið/ „die Bäume“ (Singular galadh) während /ŋg/ erscheint als Mutation eines /g/, das aus einer älteren Konsonantenverbindung /g/ stammt (z. B. in·Gelydh /iŋ'gɛlyð/ „die Ñoldor“ (Singular Golodh). Die Stelle vom Mittelpunkt (oder Leerzeichen) macht die Transkription eindeutig, doch ist Tolkiens Gebrauch in der Tat sehr gemischt.
Wir haben also entschieden, ng als /ŋ/ noldo am Wortanfang und Wortende und als /ŋg/ anga/nasal im Wortmitte zu transkribieren. Am Wortanfang erlaubt der Mittelpunkt oder Bindestricht, die passende Mutation anzugeben: die Verbindung ·ng bedeutet /ŋ/ und die Verbindung n·g bedeutet /ŋg/. Die zusätzlichen Verbindungen ngg, ŋg, ñg entsprechen auch /ŋg/ und werden alle anga/nasal transkribiert.
Lenierung, Elision, Apostroph und Gasdil
Gasdilgasdil ist ein stummer Tengwa, der ein durch Lenierung verschwundenes /g/ bedeutet. Tolkien kennzeichnete es manchmal durch einen Apostroph, doch benutzte er ihn auch für Elision verschiedener Vokale, die in Tengwar durch bloßen Wegfall des verschwundenen Lauts erscheint. Deshalb kann der Apostrophs mehrdeutig sein. Eine Option erlaubt, entweder jeden Apostroph für ein Leerzeichen zu halten, oder jeden Apostroph durch Gasdil zu transkribieren. Man kann auch das Gasdil mit dem Gradzeichen ° gerade buchstabieren. Um eindeutig zu schreiben empfehlen wir, den Apostroph nur für Elision zu benutzen (also die Leerzeichensoption zu wählen) und das Gasdil mit ° zu spezifizieren.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
„Klassischer“ Tengwar-Modus für Sindarin/Noldorin, mit Tehtar für Vokale, von dem dritten Manuskript der Brief des Königs in Sauron Defeated S. 131 veranschaulicht. Eine besondere Verwendung des allgemeinen Gebrauchs des Dritten Zeitalters, von der eine ausführliche Analyse auf Englisch von Måns Björkman Berg auf Amanyë Tenceli und eine kürzere auf Deutsch von Gernot Katzer vorliegen.
Mittelpunkt und Bindestrich
Der Mittelpunkt · dient als Wörteverbindung, besonders zwischen einem grammatischen Wort, das eine Mutation bewirkt, und dem folgenden Wort, dessen Anfang diese Mutation bezeigt. Man kann ihn auch benutzen, um den Digraph ng eindeutig zu machen: weiter unten. Komponenten mit Mittelpunkt oder Bindestrich als Wörterverbindung werden als ein einziges Wort transkribiert. In Betracht der Verwendbarkeit kann man das Sternchen * genauso benutzen.
Als Wörteverbindung gebrauchte Tolkien auch den Bindestricht, aber er gab ihn zugleich einen anderen Zweck als Trenner der Bestandteile einer Zusammensetzung, mit Einfluss auf der Tengwarschreibung. Zum Beispiel schreibt er in seiner Transkription von A Elbereth Gilthoniel in Beleriand-Modus das Doppelwort palan-dírielparma/osse/lambe/osse/ore/ando/telco/e/romen/telco/yanta/lambe statt parma/osse/lambe/osse/ando/nasal/telco/e/romen/telco/yanta/lambe: die Trennung der zwei Komponenten wird durch zwei einzelne Tengwar bezeigt, obwohl ein Konsonant mit vorstehendem Nasal am selben Artikulationsort in Wortmitte am häufigsten durch einen Tengwa mit überstehendem Tilde transkribiert wird.
Wir haben beschlossen, den Bindestricht defaultmäßig für eine Trennung zu halten (ganz wie ein Leerzeichen). So kann man die zwei Funktionen durch verschiedene von Tolkien gebrauchte Zeichen unterscheiden: der Mittelpunkt · dient als Verbindung und der Bindestricht - als Trennung. Mann muss aber zugeben, dass diese Unterscheidung ihm fremd ist: in seinen Texten hat jedes der Zeichen in gleicher Weise manchmal die eine, manchmal die andere Funktion.
Eine Option erlaubt aber, den Bindestrich wie den Mittelpunkt als Verbindung zu benutzen. Auf diesem Fall kann man dennoch wenn Nnötig eine Trennung aufzwingen, und zwar mit dem senkrechten Strich |, der in jedem Glǽmscribe-Modus eine Worttrennung bedeutet.
Transkription von ng
Der Digraph ng wird in Tolkiens Umscrift von Sindarin zweierlei gebraucht: in Wortmitte bedeutet er die Konsonantenverbindung /ŋg/, am Wortende bedeutet er den einfachen Nasalkonsonant /ŋ/. Am Wortanfang sind vermutlich beide möglich, doch immer als Mutation eines /g/ nach verschiedenen Artikeln oder Präpositionen: /ŋ/ erscheint als Mutation eines alten einfachen /g/ (z. B. i·ngelaidh /i'ŋɛlaið/ „die Bäume“ (Singular galadh) während /ŋg/ erscheint als Mutation eines /g/, das aus einer älteren Konsonantenverbindung /g/ stammt (z. B. in·Gelydh /iŋ'gɛlyð/ „die Ñoldor“ (Singular Golodh). Die Stelle vom Mittelpunkt (oder Leerzeichen) macht die Transkription eindeutig, doch ist Tolkiens Gebrauch in der Tat sehr gemischt.
Wir haben also entschieden, ng als /ŋ/ noldo am Wortanfang und Wortende und als /ŋg/ anga/nasal im Wortmitte zu transkribieren. Am Wortanfang erlaubt der Mittelpunkt oder Bindestricht, die passende Mutation anzugeben: die Verbindung ·ng bedeutet /ŋ/ und die Verbindung n·g bedeutet /ŋg/. Die zusätzlichen Verbindungen ngg, ŋg, ñg entsprechen auch /ŋg/ und werden alle anga/nasal transkribiert.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Tengwar-Modus für Telerin, für Glǽmscrafu entwickelt. Abgeleitet vom klassichen Quenya-Modus, den Tolkien im Anhang E des Herrn der Ringe beschreibt und das Namárië-Manuskript in The Road Goes Ever On S. 65 veranschaulicht, von dem eine ausführliche Analyse auf Englisch von Måns Björkman Berg auf Amanyë Tenceli und eine kürzere auf Deutsch von Gernot Katzer vorliegen. Eigentümlich werden die selbstständigen Konsonanten d, b, g und v durch die sechste Reihe der Tengwar (mit gekürztem Stamm und einfachem Bogen) geschrieben.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Sarati-Modus für Valarin, nach Tolkiens allgemeiner Bestimmung für Sarati, „phonetische Form“ genannt. Eine ausführliche Analyse auf Englisch von Måns Björkman Berg liegt auf Amanyë Tenceli vor.
Tengwar-Modus für Adûnaïsch nach dem allgemeinen Gebrauch des Dritten Zeitalters, von dem eine ausführliche Analyse auf Englisch von Måns Björkman Berg auf Amanyë Tenceli und eine kürzere auf Deutsch von Gernot Katzer vorliegen.
Rohtengwargebrauch
Dieser Modus ist wie alle Tengwarmodi mit der „Rohtengwar“ Funktionalität ausgestattet. Sie erlaubt das gerade Buchstabieren einer Tengwarreihe, die in der Transkription unverändert bleiben muss – das kann nützlich sein, um einen Tengwartext einzufügen, die zu der Moduskonfiguration nicht passt. Für weitere Information wird die Gebrauchsanweisung mit der Taste romen/ara/o rechts oben auf der Schnittstelle entfaltet.
Die Werke von John Ronald Reuel und Christopher Tolkien unterliegen dem Urheberrecht ihrer Autoren oder Rechtsnachfolger, darunter ihrer Verlage und des Tolkien Estate.
Zitate von anderen Autoren, Herausgebern und Übersetzern, die in der Bibliographie stehen, unterliegen dem Urheberrecht ihrer Autoren oder Rechtsnachfolger, wenn die Regelschutzfrist nicht abgelaufen ist.
☆
Letzte Aktualisierung der Website: 22. September 2022. Kontakt:


 ✵
✵
 Glǽmscribe – Der Transkriptor für Tolkiens Sprachen
Glǽmscribe – Der Transkriptor für Tolkiens Sprachen





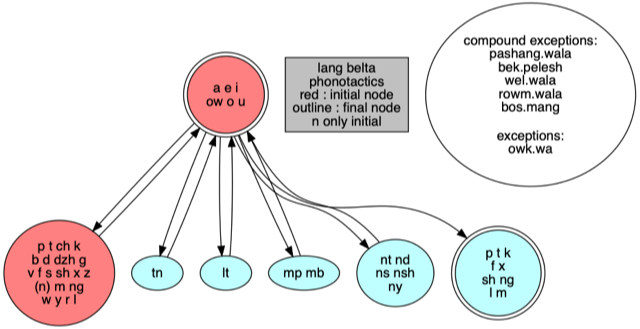


.jpg){kind=link}